Kiểm thử hệ thống

Giới thiệu
Khác với các hệ thống phần mềm truyển thống: một developer ngồi nghĩ ra các rule và lập trình bằng Python, Java, hoặc... LOLCODE, thì ML model sẽ tự sinh ra các rule sử dụng dữ liệu được cung cấp. Điều này đương nhiên là tốt, vì không phải rule nào con người cũng nghĩ ra được, tuy nhiên nó cũng có mặt trái của nó: rule được sinh ra có thể thay đổi, theo hướng tốt, xấu hoặc bị BUG. Điều này dẫn tới việc kiểm thử và debug một hệ thống ML không hề đơn giản.
Ở bài học này chúng ta hãy cùng tìm hiểu về vấ n đề hóc búa này: kiểm thử trong hệ thống ML.
graph LR
n01[ ] --"Đầu vào"--> n1[Hệ thống phần mềm<br>truyền thống] --Kết quả--> n02[ ]
n03[ ] --Thuật toán--> n1
n04[ ] --"Đầu vào"--> n2[Hệ thống<br>Machine Learning] --"Thuật toán<br>(model)"--> n05[ ]
n06[ ] --Kết quả<br>mong muốn--> n2
style n01 height:0px;
style n02 height:0px;
style n03 height:0px;
style n04 height:0px;
style n05 height:0px;
style n06 height:0px;Kiểm thử hệ thống phần mềm truyền thống
Thông thường có 2 loại kiểm thử phần mềm:
- Functional Testing: kiểm tra xem hệ thống đã đảm bảo yêu cầu về chức năng chưa, ví dụ ấn tắt windows update mãi mà nó vẫn update thì không được
- Non-functional Testing: kiểm tra xem hệ thống có đáp ứng được kỳ vọng của khách hàng không, ví dụ tất cả người trên thế giới cùng ấn nút tham gia group MLOpsVN thì group cũng không được sập
Functional Testing
Thông thường loại này bao gồm:
- Unit testing: test từng module nhỏ
- Integration testing: test một module lớn bao gồm nhiều module nhỏ để đảm bảo khi kết hợp không xảy ra vấn đề gì
Tip
Theo nguyên tắc KISS, hãy luôn cố gắng bẻ vấn đề thành nhiều module đủ nhỏ và đủ dễ hiểu.
Ví dụ dưới đây được trích từ Machine learning mastery blog cho thấy tác giả đã áp dụng rất tốt nguyên tắc này, thể hiện qua việc cố gắng sử dụng nhiều hàm nhất có thể, ví dụ train_test_split, accuracy_score và confusion_matrix, khi đó chuyện test và debug sẽ dễ dàng hơn rất nhiều.
- Regression testing: kiểm tra lại toàn bộ chức năng của hệ thống mỗi khi có thay đổi của một hoặc vài chức năng nào đó
- Smoke testing: chạy một bài test cơ bản với chức năng tối thiểu để xem hệ thống sẵn sàng cho việc test chưa Một ví dụ đơn giản: Bắt đầu kiểm tra một hệ thống bóng đèn, vừa ấn nút xong khói (smoke) bốc lên nghi ngút thì không được
Non-functional Testing
- Load testing: xác định độ chịu tải, SLA (Service Level Agreement) của hệ thống
- Stress testing: đánh giá hành vi của hệ thống tại các điều kiện không lường trước, ví dụ một phần hệ thống đột nhiên shutdown thì phản hồi có chấp nhận được không
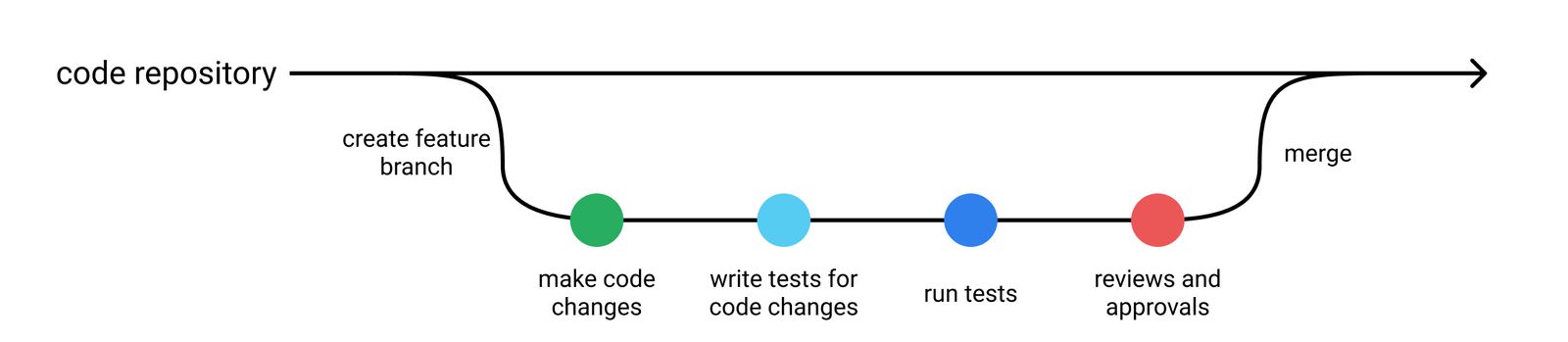
Luồng phát triển phần mềm cơ bản
Thông thường, các developer tuân thủ một số quy ước sau khi phát triển phần mềm:
- Không merge code nếu chưa chạy các test case
- Luôn viết code test khi commit logic mới
- Khi fix bug, luôn viết code test để bắt bug và phòng xảy ra trường hợp tương tự trong tương lai
Hệ thống ML cần kiểm thử những gì?
Những bài test cho hệ thống phần mềm có thể ứng dụng cho hầu hết ML code, tuy nhiên vẫn chưa để đủ đảm bảo hệ thống ML có thể hoạt động với độ tin cậy cao.

Để hệ thống ML tin tưởng được thì cần kiểm tra thêm những phần sau:
-
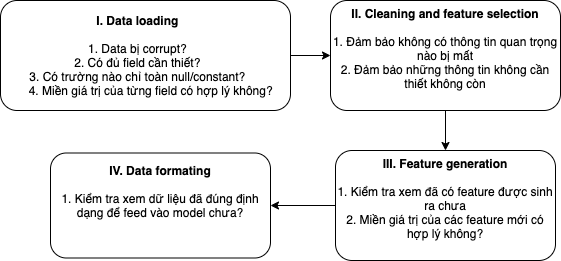
Data pipeline testing: đảm bảo dữ liệu không bị corrupt, đúng format và đúng schema (kiểu dữ liệu), ...
Data là một phần không thể thiếu trong một hệ thống ML, do đó duy trì một data pipeline với độ tin cậy cao là điều rất quan trọng. Hình dưới đây là ví dụ về 1 data pipeline và những thứ yếu tố cần cân nhắc ở mỗi bước:
-
Model testing: đảm bảo model đạt hiểu quả (ví dụ accuracy) như mong muốn và model có consistent không, ...
Có thể chia thành 2 loại model testing:
-
Testing
- Pre-train testing: tìm bug trước khi train/evaluate
- Kiểm tra xem có data leakage (leak thông tin), ví dụ observation trong tập train cũng có ở tập validation/test
- Kiểm tra xem có feature leakage (feature mang thông tin của label)
- Kiểm tra model output có shape hoặc có miền giá trị như ý muốn
-
Post-train testing: hoạt động của model (model behavior) có như ý muốn ở các tình huống (scenarios) khác nhau?
-
Invariance testing: mô tả những thay đổi của input mà không làm thay đổi kết quả dự đoán của model Ví dụ: trong bài toán sentiment analysis, thì 2 câu sau nên có cùng một output:
- Bộ phim A hay quá!
- Bộ phim B hay quá!
- Directional expectation test: mô tả những thay đổi của input sẽ làm thay đổi kết quả dự đoán của model một cách có thể lường trước. Ví dụ: trong bài toán dự đoán giá nhà, có thể đoán trước nếu không gian tăng thì giá nhà sẽ tăng.
- Bias/Fairness: kiểm tra xem model có dự đoán công bằng không, ví dụ dự đoán income của người châu Mỹ chính xác hơn người châu Á, chứng tỏ model đang bị bias.
- Model Output Consistency: với cùng 1 dữ liệu đầu vào, model output có bị thay đổi sau nhiều lần chạy khác nhau không?
Note: Công cụ What-If hỗ trợ rất tốt trong việc kiểm tra model behavior ở các tình huống khác nhau.
-
Evaluation: đánh giá hiệu quả của model thông qua các metrics như accuracy và F1, ... trên tập validation/test.
Một số tool hay dùng để test và debug
- pdb để debug python code
- pytest là framework hỗ trợ viết code test
- Coverage.py để xác định đoạn code nào có thể được execute nhưng đã không
- pylint để kiểm tra lỗi cú pháp/logic
Tổng kết
Ở bài học vừa rồi, chúng ta đã tìm hiểu về kiểm thử phần mềm truyền thống, cũng như trong ML và các tool hữu ích để triển khai quá trình kiểm thử này. Hy vọng tài liệu này giúp ích cho bạn trong việc đảm bảo hệ thống ML đáng tin cậy hơn.
Tài liệu tham khảo
- https://serokell.io/blog/machine-learning-testing
- https://developers.google.com/machine-learning/testing-debugging/common/overview
- Emmanuel Ameisen, Building Machine Learning Powered Applications: Going from Idea to Product
- https://www.jeremyjordan.me/testing-ml/
- https://homes.cs.washington.edu/~marcotcr/acl20_checklist.pdf
- https://fontysblogt.nl/software-engineering-for-machine-learning-applications/
- https://futurice.com/blog/differences-between-machine-learning-and-software-engineering
- https://www.geeksforgeeks.org/differences-between-functional-and-non-functional-testing/
- https://eugeneyan.com/writing/testing-ml/