Xây dựng pipeline

Giới thiệu
Ở bài học trước, chúng ta đã làm quen với feature store, Feast và dùng command feast apply để tạo ra feature definition ở đường dẫn data_pipeline/feature_repo/registry/local_registry.db. Trong bài học này chúng ta sẽ sử dụng folder này để cấu hình client store giao tiếp với feature store như sau:
- Khởi tạo client store để giao tiếp với feature store
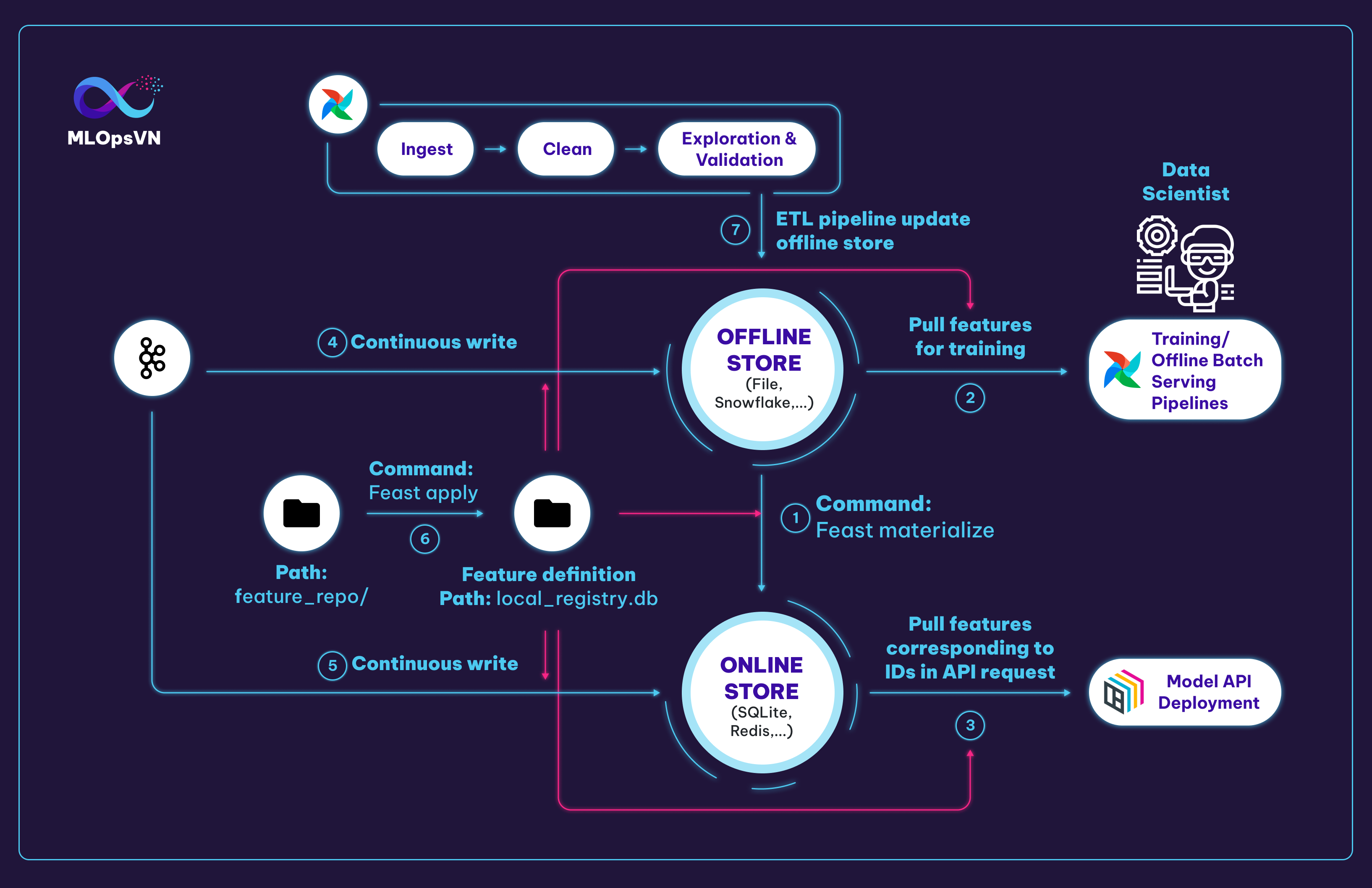
Client này sẽ được sử dụng ở nhiều bước khác nhau bao gồm 1, 2, 3, 4, 5 như hình dưới đây:
Môi trường phát triển
Ngoài Feast, bài học này sẽ sử dụng thêm Airflow, bạn vào repo mlops-crash-course-platform/ và start service này như sau:
Các tương tác chính với Feast
Chúng ta có 6 tương tác chính với Feast như sau:
1. Materialize feature từ offline sang online store để đảm bảo online store lưu trữ feature mới nhất
| data_pipeline/scripts/feast_helper.sh | |
|---|---|
Tip
Để hiểu rõ hơn về materialize, giả sử rằng ở offline store chúng ta có 3 record của ID 1001 như sau:
| datetime | driver_id | conv_rate | acc_rate | avg_daily_trips | created |
|---|---|---|---|---|---|
| 2021-07-13 11:00:00+00:00 | 1001 | 0.852406 | 0.059147 | 340 | 2021-07-28 11:08:04.802 |
| 2021-08-10 12:00:00+00:00 | 1001 | 0.571599 | 0.244896 | 752 | 2021-07-28 11:08:04.802 |
| 2021-07-13 13:00:00+00:00 | 1001 | 0.929023 | 0.479821 | 716 | 2021-07-28 11:08:04.802 |
Khi chúng ta chạy command feast materialize 2021-08-07T00:00:00, thì dữ liệu có datetime mới nhất mà trước thời điểm 2021-08-07T00:00:00 sẽ được cập nhật vào online store. Đó chính là record thứ 3 ở bảng trên.
| datetime | driver_id | conv_rate | acc_rate | avg_daily_trips | created |
|---|---|---|---|---|---|
| 2021-07-13 13:00:00+00:00 | 1001 | 0.929023 | 0.479821 | 716 | 2021-07-28 11:08:04.802 |
2. Data scientist, training pipeline hoặc offline batch serving pipeline kéo features về để train model
3. Kéo features mới nhất tương ứng với các IDs trong request API để cho qua model dự đoán
4. Đẩy stream feature vào offline store
5. Đẩy stream feature vào online store
7. ETL (Extract, Transform, Load) pipeline cập nhật dữ liệu của offline store
Tip
Ở tương tác 2., thông thường các Data Scientist sẽ kéo dữ liệu từ feature store để:
- thực hiện POC
- thử nghiệm với các feature khác nhằm mục đích cải thiện model
Ở công đoạn xây dựng data pipeline, chúng ta sẽ xây dựng pipeline cho các tương tác 1., 4., 5., 7.
Xây dựng các pipelines
ETL pipeline
Để tạo ra một Airflow pipeline, thông thường chúng ta sẽ làm theo trình tự sau:
- Định nghĩa DAG cho pipeline (line 1-8)
- Viết các task cho pipeline, ví dụ: ingest_task, clean_task và explore_and_validate_task (line 9-25)
- Viết thứ tự chạy các task (line 27)
-
Chạy lệnh sau để build Docker image cho các pipeline component, và copy file code DAG sang folder
airflow/run_env/dags/data_pipelinecủa repo clone từ MLOps Crash course platform- Copy
data_pipeline/dags/*vào folderdagscủa Airflow
DAG dưới đây thể hiện ETL pipeline.
- Định nghĩa tên pipeline hiển thị ở trên Airflow dashboard
- Định nghĩa pipeline owner, số lần retry pipeline, và khoảng thời gian giữa các lần retry
- Lịch chạy pipeline, ở đây
@oncelà một lần chạy, bạn có thể thay bằng cron expression ví dụ như 0 0 1 * * - Ngày bắt đầu chạy pipeline theo múi giờ UTC
- Nếu start_date là ngày 01/01/2022, ngày deploy/turn on pipeline là ngày 02/02/2022, và schedule_interval là @daily thì sẽ không chạy các ngày trước 02/02/2022 nữa
- Command chạy trong docker container cho bước này
- Định nghĩa thứ tự chạy các bước của pipeline: đầu tiên là ingest sau đó tới clean và cuối cùng là explore_and_validate
Info
Do chúng ta dùng DockerOperator để tạo task nên cần phải build image chứa code và môi trường trước, sau đó sẽ truyền tên image vào
DEFAULT_DOCKER_OPERATOR_ARGStrong từng pipeline component (ví dụ như line 11). Dockerfile để build image bạn có thể tham khảo tạidata_pipeline/deployment/DockerfileBiến
DefaultConfig.DEFAULT_DOCKER_OPERATOR_ARGSchứa các config như sau:- Docker image dùng cho task
- Tự động xác định Docker engine API version
- Tự động dọn dẹp container sau khi exit
- Folder ở máy local, bắt buộc là đường dẫn tuyệt đối
- Folder nằm trong docker container
- Kiểu bind, đọc thêm ở đây
- Copy
-
Đăng nhập vào Airflow tại http://localhost:8088, account
airflow, passwordairflow, các bạn sẽ thấy một DAG với tên db_to_offline_store, 2 DAG bên dưới chính là những pipeline còn lại trong data pipelines (đề cập ở bên dưới).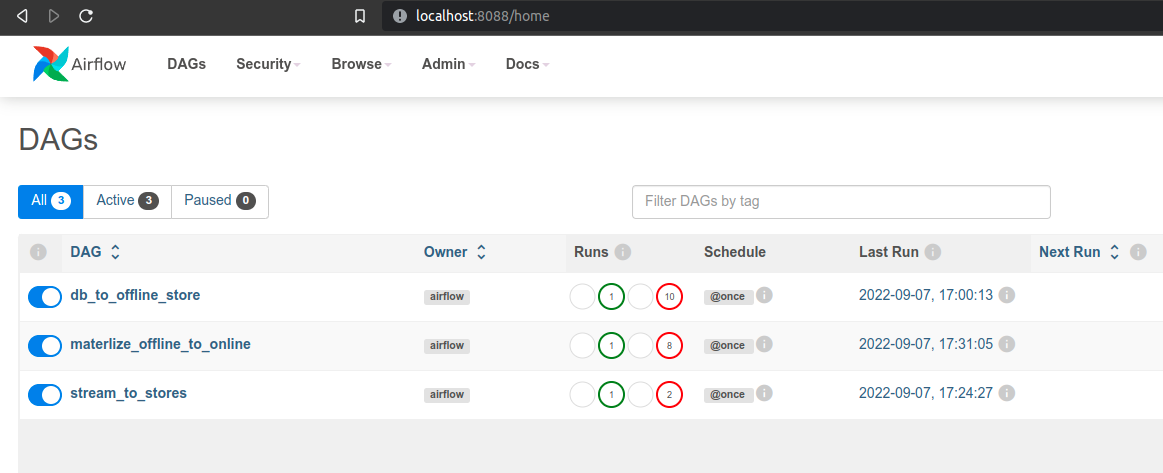
-
Đặt Airflow Variable
MLOPS_CRASH_COURSE_CODE_DIRbằng đường dẫn tuyệt đối tới foldermlops-crash-course-code/. Tham khảo hướng dẫn này về cách đặt Airflow Variable.Info
Airflow Variable
MLOPS_CRASH_COURSE_CODE_DIRđược dùng trong filedata_pipeline/dags/utils.py. Variable này chứa đường dẫn tuyệt đối tới foldermlops-crash-course-code/, vìDockerOperatoryêu cầuMount Sourcephải là đường dẫn tuyệt đối. -
Kích hoạt data pipeline và đợi kết quả
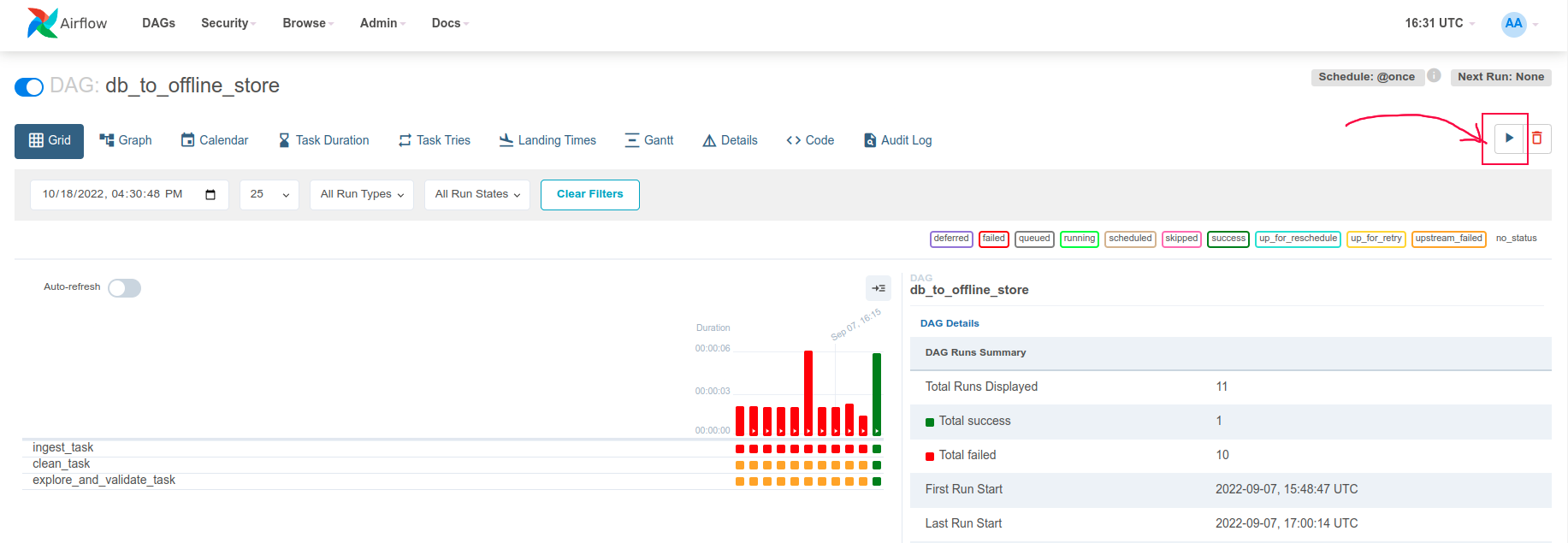
-
Xem thứ tự các task của pipeline này như sau:
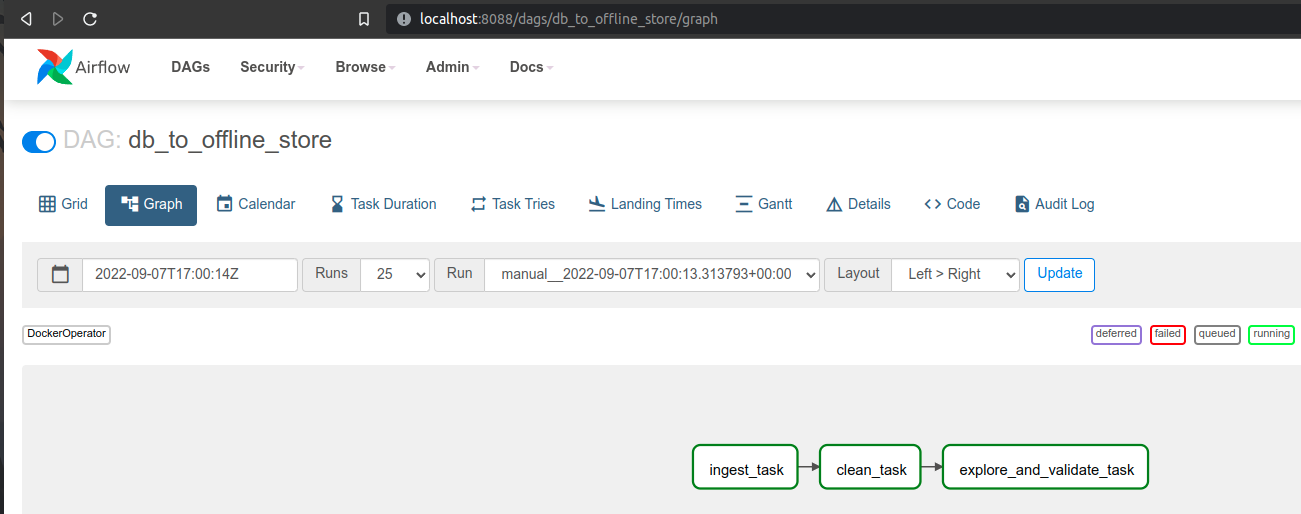
Tương tự như ETL pipeline, chúng ta sẽ code tiếp Feast materialize pipeline và Stream to stores pipeline như bên dưới.
Feast materialize pipeline
Materialize dữ liệu từ offline qua online giúp làm mới dữ liệu ở online store
Stream pipeline
Trong phần này, chúng ta sẽ làm mới features bằng cách ghi dữ liệu trực tiếp từ stream source vào offline và online store.
Ở bài trước, chúng ta đã chạy Kafka stream. Đoạn code dưới đây sẽ thực hiện tác vụ đọc và xử lý data từ Kafka stream và lưu vào offline store và online store. Khi bạn sử dụng thư viện Feast trong đoạn code training hay inference để đọc features, bạn sẽ thấy features được cập nhật mới liên tục. Các đoạn code training và inference này sẽ được hướng dẫn trong các bài tiếp theo.
Tổng kết
Ở bài học này, chúng ta đã sử dụng Feast SDK để lưu trữ và lấy feature từ feature store. Để đảm bảo feature luôn ở trạng thái mới nhất có thể, chúng ta cũng đã xây dựng các Airflow pipeline để cập nhật dữ liệu định kỳ cho các store.
Chúng ta cũng hoàn thành chuỗi bài về data pipeline, hy vọng bạn có thể vận dụng các kiến thức đã học để vận hành hiệu quả các luồng dữ liệu và luồng feature của mình.