Training pipeline

Giới thiệu
Sau khi thực hiện ít nhất một dự án POC thành công, chúng ta đã có được:
- Cách biến đổi data từ data source
- Cách biến đổi feature engineering
- Code chuẩn bị data để train model
- Code train model
- Code đánh giá model
Phần 1, 2 được dùng trong bài xây dựng data pipeline. Phần 3, 4 và 5 sẽ được dùng trong bài này để xây dựng training pipeline với các task như hình dưới.
flowchart LR
n1[1. Cập nhật<br>Feature Store] --> n2[2. Data<br>extraction] --> n3[3. Data<br>validation] --> n4[4. Data<br>preparation] --> n5[5. Model<br>training] --> n6[6. Model<br>evaluation] --> n7[7. Model<br>validation]Môi trường phát triển
Các bạn làm các bước sau để cài đặt môi trường phát triển:
-
Cài đặt môi trường Python 3.9 mới với các thư viện cần thiết trong file
training_pipeline/dev_requirements.txt -
Đặt environment variable
TRAINING_PIPELINE_DIRở terminal bạn dùng bằng đường dẫn tuyệt đối tới foldertraining_pipelinevàMLFLOW_TRACKING_URIbằng URL của MLflow server. Hai env var này hỗ trợ chạy python code ở foldertraining_pipeline/srctrong quá trình phát triển.
Các MLOps tools được dùng trong bài này bao gồm:
- Feast: truy xuất Feature Store
- MLflow: ML Metadata Store, Model Registry
- Airflow: điều phối training pipeline
Note
Trong quá trình chạy code cho tất cả các phần dưới đây, chúng ta giả sử rằng folder gốc nơi chúng ta làm việc là folder training_pipeline.
Cập nhật Feature Store
Trong khoá học này, Feast được dùng làm Feature Store để quản lý phiên bản các features và các bộ features. Feast sử dụng Feature Registry để tập trung lưu trữ định nghĩa về các feature và metadata. Do Feature Registry này được lưu ở dạng file ở máy local, nên mỗi Data Scientist cần tự update Feature Registry trên máy của mình.
Trước khi cập nhật Feature Store, cần đảm bảo code của Feature Store đã được triển khai lên máy của bạn. Trong thực tế, code của Feature Store sẽ được Data Engineer build và release như một library cho phép ML engineer download về và sử dụng.
Code của Feature Store nằm tại data_pipeline/feature_repo. Để triển khai sang training pipeline, chúng ta sẽ copy code từ data_pipeline/feature_repo sang training_pipeline/feature_repo. Bạn hãy chạy các lệnh sau.
cd ../data_pipeline
make deploy_feature_repo # (1)
cd ../training_pipeline
cd feature_repo
feast apply # (2)
cd ..
- Triển khai code của Feature Store
- Cập nhật Feature Registry và Offline Feature Store của Feast
Data extraction
Trong task này, các features được lấy từ Offline Feature Store để phục vụ cho quá trình train model.
- Đầu vào: tên các features chúng ta muốn lấy
- Đầu ra: file data chứa features được lưu vào disk
Code của task này được lưu tại training_pipeline/src/data_extraction.py.
- Tạo kết nối tới Feature Store
- Đọc label từ file
driver_orders.csv - Định dạng lại format cho cột
event_timestamp - Download features từ Offline Feature Store.
- Các feature chúng ta muốn lấy bao gồm
conv_rate,acc_ratevàavg_daily_trips.driver_statslà tênFeatureViewmà chúng ta đã định nghĩa tạidata_pipeline/feature_repo/features.py - Cách mà Feast lấy ra features giống như cách chúng ta chuẩn bị data ở dự án POC. Bạn có thể xem lại tại đây.
- Lưu data vào disk để sử dụng trong các task tiếp theo.
Bạn làm các bước sau để test thử code.
-
Chạy code
-
Kiểm tra folder
training_pipeline/artifacts, bạn sẽ thấy filetraining.parquet
Data validation

Sau khi lấy được data từ Offline Feature Store, chúng ta cần đánh giá data có hợp lệ không trước khi train model, bằng cách kiểm tra.
-
Cấu trúc data
-
Nhận được feature nào không mong muốn không?
- Nhận đủ feature mong muốn không?
-
Feature có ở format mong muốn không?
-
Giá trị của data
-
Các tính chất thống kê của data có như mong muốn không?
- Các giả sử về data có như mong muốn không?
Task này không sinh ra các artifact hay file nào, mà nó sẽ quyết định xem task tiếp theo có được thực hiện hay không. Code của task này được lưu tại training_pipeline/src/data_validation.py.
- Kiểm tra xem có feature nào không mong muốn
config.feature_dictlà dictionary với key là tên các feature mong muốn và value là format mong muốn của các feature- Kiểm tra xem có feature mong muốn và ở định dạng mong muốn không
Để đơn gian hoá code và tập trung vào MLOps, chúng ta sẽ không kiểm tra các tính chất thống kê của data. Bạn làm các bước sau để test thử code.
Data preparation
Task Data preparation có đầu vào và đầu ra như sau.
- Đầu vào: file data chứa features ở bước Data extraction
- Đầu ra: training set và test set đã được lưu vào disk
Task này thực hiện các việc sau.
- Biến đổi data nếu cần, có thể xảy ra nếu features lấy từ Offline Feature Store không ở định dạng mong muốn
- Biến đổi feature engineering nếu cần
- Tạo training set, test set để train và đánh giá model
Code của task này được lưu tại training_pipeline/src/data_preparation.py.
- Chia data ra thành training set và test set, vì giả sử chúng ta đã lấy được các feature mong muốn ở định dạng mong muốn, cũng không cần thực hiện thêm các bước biển đổi data, hoặc sinh ra các feature khác nữa
- Lưu data vào disk để sử dụng trong các task tiếp theo.
Bạn làm các bước sau để test thử code.
-
Chạy code
-
Kiểm tra folder
training_pipeline/artifacts, bạn sẽ thấy các filestraining.parquet,train_x.parquet,test_x.parquet,train_y.parquetvàtest_y.parquet
Model training
Task Model training sẽ train model và thực hiện hyperparameter tuning để train model tốt nhất. Tuy nhiên trong bài này, chúng ta sẽ không thực hiện hyperparameter tuning. Task này có:
- Đầu vào: data được chuẩn bị ở task Data preparation
- Đầu ra: model đã được train
Code cho task Model training đã được viết ở dự án POC. Code của task này được lưu tại training_pipeline/src/model_training.py.
- Set URI tới MLflow server
- Load data
- Train model
- Log metadata
- Lưu lại thông tin về lần chạy hiện tại để các task tiếp theo biết được model nào vừa được train, để có thể download model và đánh giá model
Ở bước Log metadata, chúng ta không cần log lại danh sách các feature được sử dụng nữa, vì bộ feature được dùng đã được version trong code ở bước Data extraction. Nếu có thể, chúng ta nên lưu cả đường dẫn tới data source để đảm bảo có thể theo dõi lại được nguồn gốc của data.
Bạn làm các bước sau để test thử code.
-
Mở repo mlops-crash-course-platform và chạy mlflow server.
-
Chạy code
-
Kiểm tra folder
training_pipeline/artifacts, bạn sẽ thấy filerun_info.json -
Mở MLflow server, bạn sẽ thấy một experiment được tạo ra
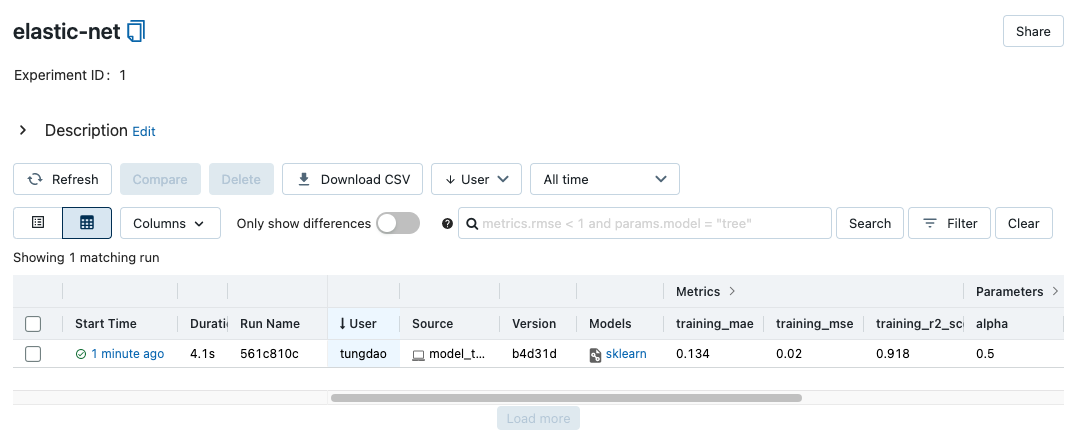
Model evaluation
Task Model evaluation thực hiện chạy prediction cho model trên test set. Task này có:
- Đầu vào: model đã được train
- Đầu ra: các metrics để đánh giá chất lượng model
Code cho task Model evaluation đã được viết ở dự án POC. Code của task này được lưu tại training_pipeline/src/model_evaluation.py.
| training_pipeline/src/model_evaluation.py | |
|---|---|
- Chạy inference trên test set
- Lưu lại kết quả
Kết quả là offline metrics, sẽ được lưu vào disk, để phục vụ cho task Model validation. Bạn làm các bước sau để test thử code.
-
Chạy code
-
Kiểm tra folder
training_pipeline/artifacts, bạn sẽ thấy fileevaluation.json
Model validation
Trong task này, chúng ta dùng các metrics từ task Model evaluation để đánh giá model. Các baseline về metrics nên được định nghĩa ở bước Phân tích vấn đề. Việc đánh giá model dựa trên các metrics để chứng tỏ model mới có performance tốt hơn model cũ trước khi triển khai ra production.
Model performance cần được đánh giá trên các phần khác nhau của dataset. Ví dụ như model mới có Accuracy cao hơn model cũ khi đánh giá trên tất cả khách hàng, nhưng có Accuracy trên data của khách hàng ở vài khu vực địa lý thấp hơn model cũ.
Ngoài ra, model có thể cần được kiểm tra xem có tương thích với hệ thống ở production không. Ví dụ:
- Kiểm tra model mới có nhận vào định dạng đầu vào và trả về định dạng đầu ra tương thích không
- Thời gian inference có đảm bảo nằm trong một khoảng yêu cầu của vấn đề kinh doanh không
Trong task này, chúng ta chỉ viết code để so sánh offline metrics với các thresholds được định nghĩa trong file training_pipeline/.env. Nếu model thoả mãn các thresholds, chúng ta có thể tự động lưu model vào Model Registry. Thông tin của model được lưu và version của nó cũng được lưu vào disk để sử dụng khi cần, ví dụ để triển khai ra production.
Code của task này được lưu tại training_pipeline/src/model_validation.py.
- Lưu model vào Model Registry nếu các offline metrics thoả mãn threshold
- Lưu lại thông tin về model
Bạn làm các bước sau để test thử code.
-
Chạy code
-
Nếu model thoả mãn các thresholds, kiểm tra folder
training_pipeline/artifacts, bạn sẽ thấy fileregistered_model_version.json -
Mở MLflow server, bạn sẽ thấy model đã được lưu vào Model Registry
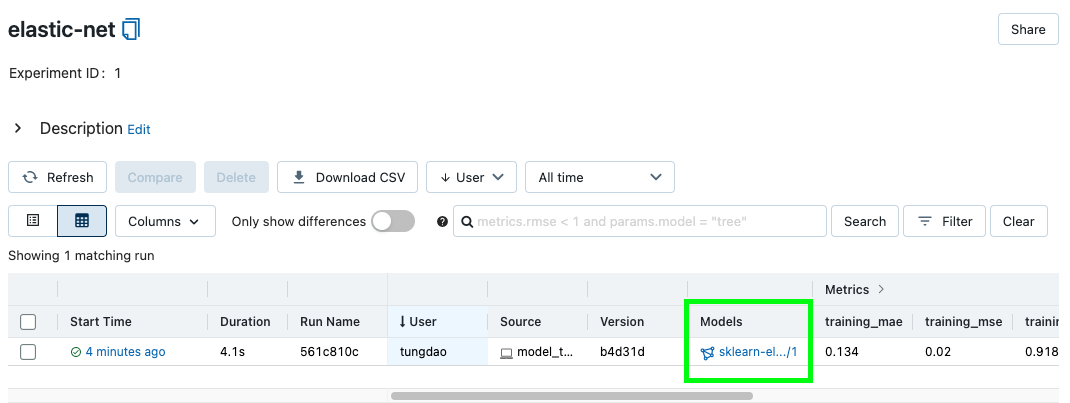
-
Click vào model để xem thêm thông tin model. Như hình dưới, MLflow đã ghi lại cả định dạng hợp lệ cho input và output của model
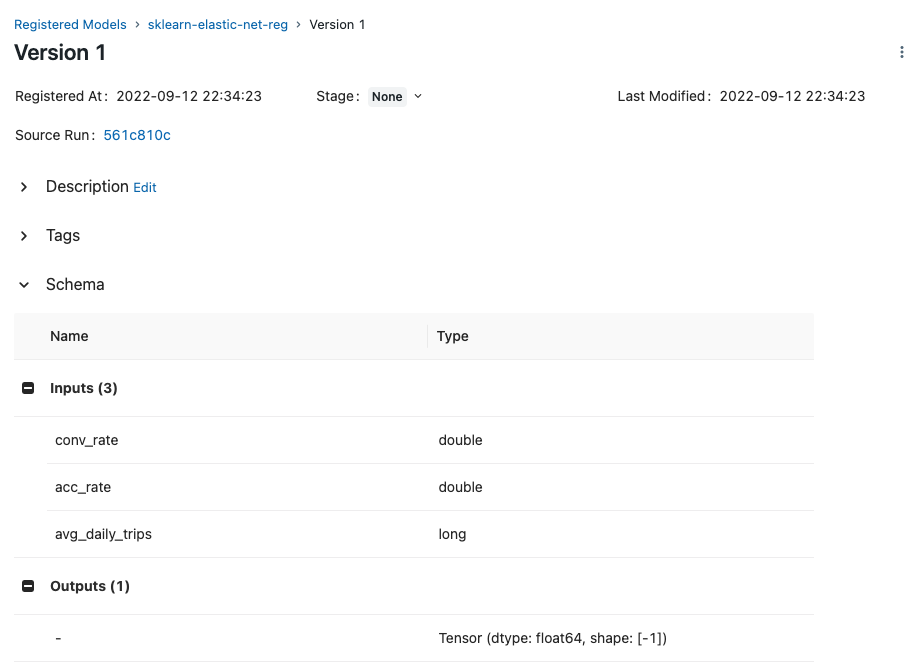
Tip
Phần Schema định nghĩa định dạng đầu vào và đầu ra của model. Định dạng này được gọi là Model Signature
Airflow DAG
Ở phần này, Airflow DAG được dùng để kết nối các task trên lại thành một DAG hay một pipeline hoàn chỉnh. Code định nghĩa Airflow DAG được lưu tại training_pipeline/dags/training_dag.py.
- DAG sẽ chạy một lần khi được bật, sau đó sẽ cần kích hoạt lại bằng tay
- Vì các task khác nhau có môi trường chạy và các dependencies khác nhau, nên
DockerOperatorđược dùng để cách ly các task trong các docker containers khác nhau. Để đơn giản, chúng ta chỉ dùng một Docker image duy nhất cho tất cả các task - Command sẽ được gọi trong mỗi task. Command này giống với command bạn đã chạy trong quá trình viết code ở trên
- Vì chỉ một docker image duy nhất dùng cho các tasks, nên chỉ cần một config chung cho các docker containers được tạo ra ở mỗi task. Config chung này được lưu trong biến
DefaultConfig.DEFAULT_DOCKER_OPERATOR_ARGS.
Tiếp theo, chúng ta cần build docker image mlopsvn/mlops_crash_course/training_pipeline:latest và triển khai Airflow DAG bằng các bước sau.
-
Đăng nhập vào Airflow UI với tài khoản và mật khẩu là
airflow. -
Đặt Airflow Variable
MLOPS_CRASH_COURSE_CODE_DIRbằng đường dẫn tuyệt đối tới foldermlops-crash-course-code/. Tham khảo hướng dẫn này để đặt Airflow Variable. -
Chạy lệnh
- Copy
training_pipeline/dags/*vào folderdagscủa Airflow
Tip
Định nghĩa về các env vars được dùng trong quá trình chạy Airflow DAG được lưu tại
training_pipeline/.env. Bạn có thể thay đổi nếu cần. - Copy
-
Kích hoạt training pipeline và đợi kết quả
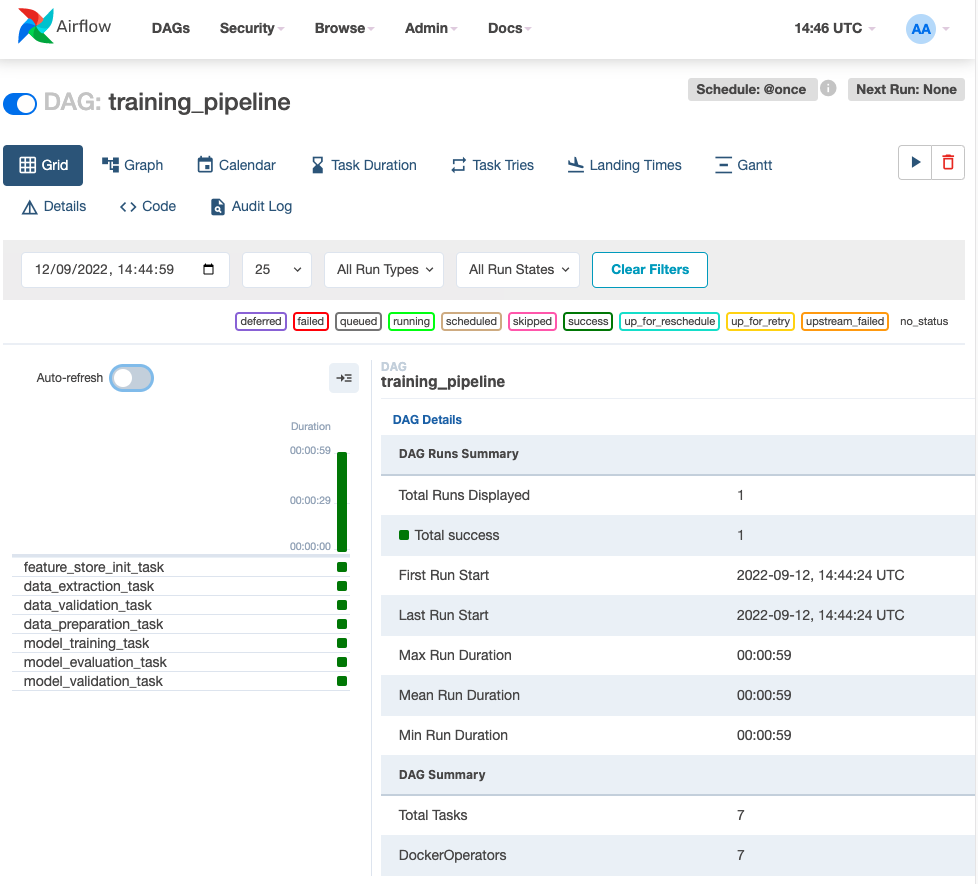
-
Sau khi Airflow DAG hoàn thành, kiểm tra MLflow server, bạn sẽ thấy metadata của lần chạy experiment mới và model train xong đã được log lại
Tổng kết
Chúng ta vừa trải qua quy trình phát triển điển hình cho training pipeline. Tuỳ thuộc vào mức độ phức tạp của dự án và các chức năng của dự án mà có thể bỏ bớt hoặc thêm vào các task khác. Các task cũng có thể được chia nhỏ ra để thực hiện các công việc đòi hỏi tính toán nặng, tránh việc phải chạy lại nhiều lần.
Trong một dự án ML, trong khi Data Scientist vẫn thực hiện các thử nghiệm trên data và model, ML engineer/MLOps engineer có thể xây dựng training pipeline được cập nhật liên tục dựa trên yêu cầu từ Data Scientist.
Sau khi tự động hoá training pipeline, trong bài tiếp theo chúng ta sẽ xây dựng và tự động hoá quá trình triển khai model.