Triển khai monitoring service
Giới thiệu
Trong bài trước, chúng ta đã thiết kế monitoring service với các công việc:
- Tạo ra dataset chứa feature bị drift
- Triển khai monitoring service để theo dõi data và model performance
- Thiết lập Grafana dashboards để hiển thị metrics về data và model
Trong bài này, chúng ta sẽ thực hiện code để triển khai service này.
Môi trường phát triển
Các bạn làm các bước sau để cài đặt môi trường phát triển:
-
Cài đặt môi trường Python 3.9 mới với các thư viện cần thiết trong file
monitoring_service/dev_requirements.txt -
Đặt environment variable
MONITORING_SERVICE_DIRở terminal bạn dùng bằng đường dẫn tuyệt đối tới foldermonitoring_service. Env var này hỗ trợ chạy python code ở foldermonitoring_service/srctrong quá trình phát triển.
Các tools sẽ được sử dụng trong bài này bao gồm:
- Feast: truy xuất Feature Store
- Flask: viết API cho monitoring service
- Evidently: kiểm tra chất lượng data và model performance
Note
Trong quá trình chạy code cho tất cả các phần dưới đây, giả sử rằng folder gốc nơi chúng ta làm việc là folder monitoring_service.
Monitoring service
Trong phần này, chúng ta sẽ thực hiện code monitoring service. Hình dưới đây thể hiện các luồng data của monitoring service.
flowchart LR
n01[ ] --Label--> n2
n0[Client] --Request--> n1[Online serving<br>service] --Features &<br>prediction--> n2[Monitoring<br>service] --Metrics--> n3[Prometheus<br>& Grafana]
n1 --Response--> n0
style n01 height:0px;Quá trình phát triển monitoring service gồm các bước chính sau.
- Viết code gửi request và response data từ Online serving API sang Monitoring API (một RESTful API) của monitoring service
- Viết Monitoring API ở monitoring service, nhận data từ Online serving API, dùng data này để theo dõi data drift và model performance
- Thiết lập Prometheus server và Grafana dashboards để hiển thị các metrics về data drift và model performance
Monitoring API
Đầu tiên, chúng ta sẽ viết Monitoring API ở monitoring service. Code của monitoring service được đặt tại monitoring_service/src/monitoring_service.py. Bạn hãy để ý tới hàm iterate của class MonitoringService với luồng xử lý data như sau.
- Hàm
iteratenhận vàonew_rows, chính là data được Online serving API gửi tới - Xử lý data nhận được
- Kiểm tra xem đã đến thời điểm chạy quá trình đánh giá data drift và model performance chưa
- Thực hiện phân tích đánh giá data drift và model performance
- Gửi metrics về data drift tới Prometheus server
- Gửi metrics về model performance tới Prometheus server
Data nhận được từ Online serving API gồm các cột chính sau.
| Cột | Ý nghĩa |
|---|---|
request_id |
Request ID |
conv_rate |
Feature |
acc_rate |
Feature |
avg_daily_trips |
Feature |
best_driver_id |
ID tài xế được chọn |
prediction |
Dự đoán của model cho driver ID được chọn |
Hãy cùng xem hàm _process_curr_data làm công việc gì.
- Hàm
_process_curr_datanhận vào data mới được gửi từ Online serving API sang - Đọc label data hay chính là
request_data - Kết hợp data mới với label data theo
request_id - Tích luỹ data mới với data hiện tại
- Bỏ bớt records nếu như số records vượt quá
WINDOW_SIZEchính là kích thước của test window - Lưu data mới đã được xử lý vào làm data hiện tại
- Kiểm tra xem đã đủ số records cần thiết chưa
Question
Tại sao cần đọc label data hay request_data mỗi khi có records mới được gửi đến từ Online serving API?
Chúng ta không cần phải đọc lại request_data mỗi khi có records mới vì request_data là không đổi. Sở dĩ code được viết như vậy là để giả sử rằng không phải lúc nào label cũng có sẵn ở production.
Sau khi kết hợp data mới với label data theo request_id data được tổng hợp chứa các cột sau:
- Các cột features: dùng để theo dõi data drift
- Cột
predictionvà cột labeltrip_completed: dùng để theo dõi model performance. Lưu ý, cộtpredictionđược biến đổi trong hàmmerge_request_with_labelđể luôn có giá trị là1
Tiếp đến, hãy xem hàm _process_next_run và _execute_monitoring.
- Kiểm tra xem thời điểm hiện tại có chạy monitoring không
- Tính thời điểm tiếp theo sẽ chạy monitoring
- Thực hiện đánh giá data drift, giống như chúng ta đã thực hiện ở file notebook
monitoring_service/nbs/test_datasets.ipynb - Thực hiện đánh giá model performance
Cuối cùng, đoạn code dưới đây của hàm _process_metrics sẽ gửi metrics của data drift và model performance tới Prometheus server.
- Tạo tên metric, phải giống với metric được dùng trong Prometheus query trên Grafana dashboards
labelslà mộtdictvới key, value là tên và giá trị của các label được quy ước bởi Evidently, ví dụ{'dataset': 'reference', 'metric': 'accuracy'}.labelsnày có ý nghĩa tương đương với Prometheus labelsself.metricslưu các objectGaugecủa Prometheus.Gaugegửi metrics tới Prometheus server. Biếnfoundlà một objectGauge, tương ứng với mỗi metric lấy ra từ Evidently- Gán Prometheus labels và giá trị cho
Gaugeobject.Gaugeobject sẽ gửi labels, giá trị của các metrics lên Prometheus server
Ngoài các đoạn code quan trọng nhất của monitoring service ở trên, các đoạn code còn lại khác mà bạn cần lưu ý như dưới đây.
- Tạo Flask app. Flask là một thư viện phổ biến được dùng để viết RESTful API trong Python
- Tự động tạo endpoint
/metricsđể Prometheus thu thập metrics - Khởi tạo
MonitoringServiceclass - Tạo endpoint
/iterateđể Online serving API gửi data tới - Biến đổi data nhận vào thành
DataFrame - Gọi hàm
iterateđể thực hiện đánh giá data drift và model performance - Chạy Flask app tại port
8309ở máy local
Để Prometheus thu thập được metrics gửi qua endpoint /metrics, bạn cần tạo 1 Prometheus Job trong file config của Prometheus server được đặt tại prom-graf/prometheus/config/prometheus.yml trong repo mlops-crash-course-platform. Prometheus Job này đã được tạo sẵn như dưới đây.
| prom-graf/prometheus/config/prometheus.yml | |
|---|---|
Sau khi code xong monitoring service, chúng ta sẽ cập nhật code trong Online serving API để gửi data tới Monitoring API sau khi model thực hiện dự đoán.
Tích hợp Online serving
Bạn mở file code của Online serving API tại model_serving/src/bentoml_service.py trong repo mlops-crash-course-code. Hãy chú ý tới đoạn code trong hàm inference.
- Lấy ra index của tài xế có khả năng cao nhất sẽ hoàn thành cuốc xe
- Lấy ra ID của tài xế được chọn
- Lấy ra record trong
DataFramegốc của tài xế được chọn - Thêm cột
request_idvàomonitor_dfvới giá trị làrequest_idđược gửi tới trong request - Thêm cột
best_driver_idvàomonitor_df. Việc lưu trữ lại thông tin về dự đoán của model là cần thiết, giúp cho việc theo dõi data và debug ở production dễ dàng hơn - Gọi tới hàm
monitor_requestđể gửi data tới Monitoring API. Data được gửi bao gồm các cột chính:request_id, các cột features,predictionvàbest_driver_id - Biến đổi
DataFramethành dạng JSON với sự hỗ trợ củaNumpyEncoderclass, giúp cho việc biến đổi JSON trở lại thànhDataFrameở phía Monitoring API dễ dàng hơn - Gửi POST request tới Monitoring API
Như vậy là chúng ta vừa tích hợp Online serving API với Monitoring API của Monitoring service. Sau khi model thực hiện dự đoán ở Online serving API, data được tổng hợp từ requests và prediction của model sẽ được gửi sang Monitoring API để được theo dõi và đánh giá. Monitoring API sẽ thực hiện việc đánh giá data drift, model performance, rồi gửi các metrics sau khi đánh giá ra API endpoint /metrics. Prometheus server sẽ định kì thu thập các metrics qua endpoint /metrics này. Grafana sẽ đọc các metrics từ Prometheus server và hiển thị lên dashboards. Trong phần tiếp theo, chúng ta sẽ thiết lập Grafana dashboards để hiển thị các metrics.
Grafana dashboards và Alerts
Có 2 dashboards chúng ta cần thiết lập, bao gồm:
monitoring_service/dashboards/data_drift.json: Dashboard cho metrics về data driftmonitoring_service/dashboards/classification_performance.json: Dashboard cho metrics về model performance
Bạn cần làm các bước sau để triển khai các dashboards này lên Grafana.
- Copy 2 file dashboards trên vào
mlops-crash-course-platform/prom-graf/run_env/grafana/dashboards - Truy cập vào Grafana server tại http://localhost:3000
- Mở 2 dashboards có tên Evidently Data Drift Dashboard và Evidently Classification Performance Dashboard
Data Drift Dashboard
Dashboard Evidently Data Drift Dashboard sẽ giống như hình dưới đây.
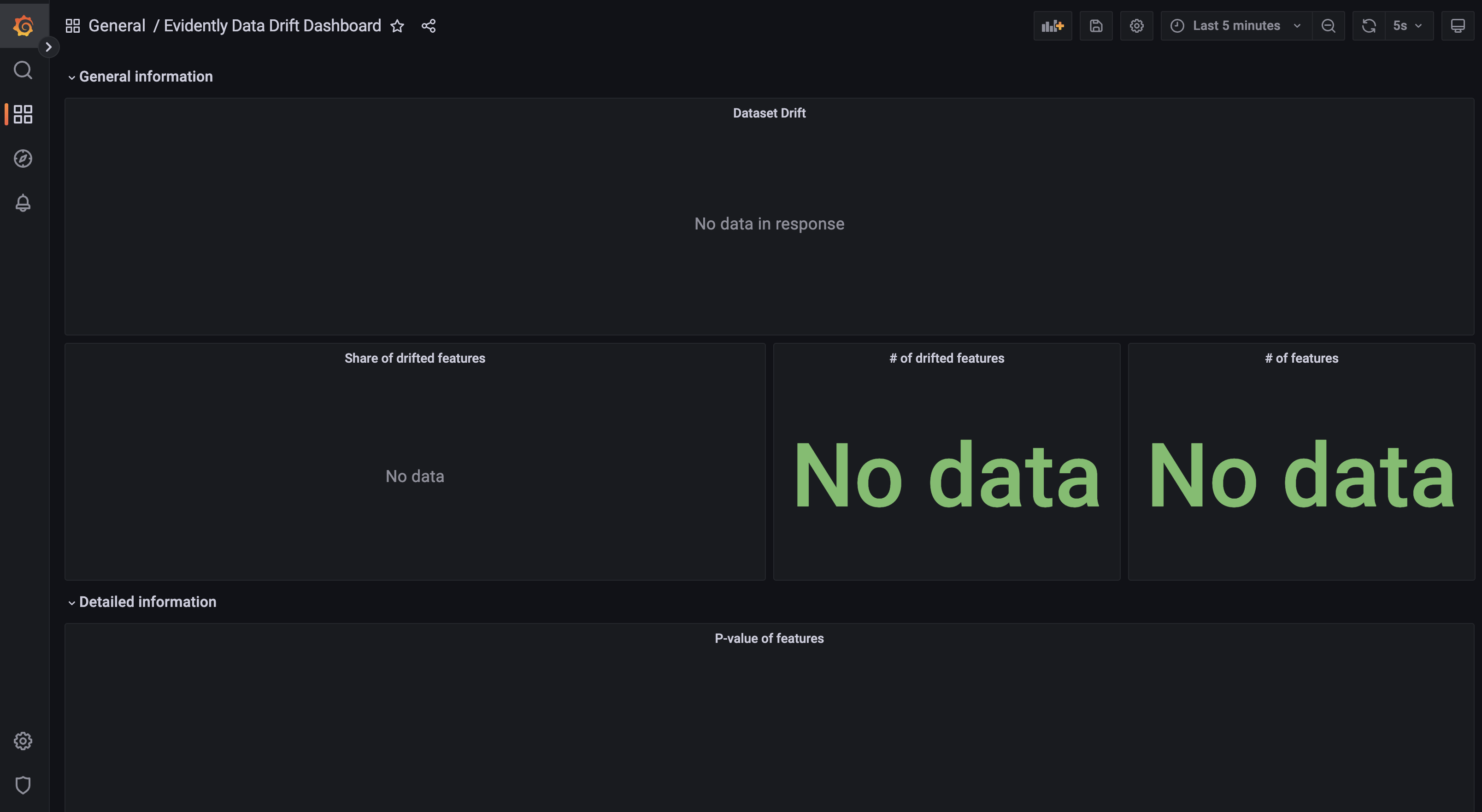
Dashboard này chứa các panels về data drift bao gồm:
-
General informationDataset drift: Dataset có bị drift hay khôngShare of drifted features: Tỉ lệ số features bị drift trên tổng số features# of drifted features: Số features bị drift# of features: Tổng số features
-
Detailed informationP-value of features: p-value của các features
Model Performance Dashboard
Dashboard Evidently Classification Performance Dashboard sẽ giống như hình dưới đây.
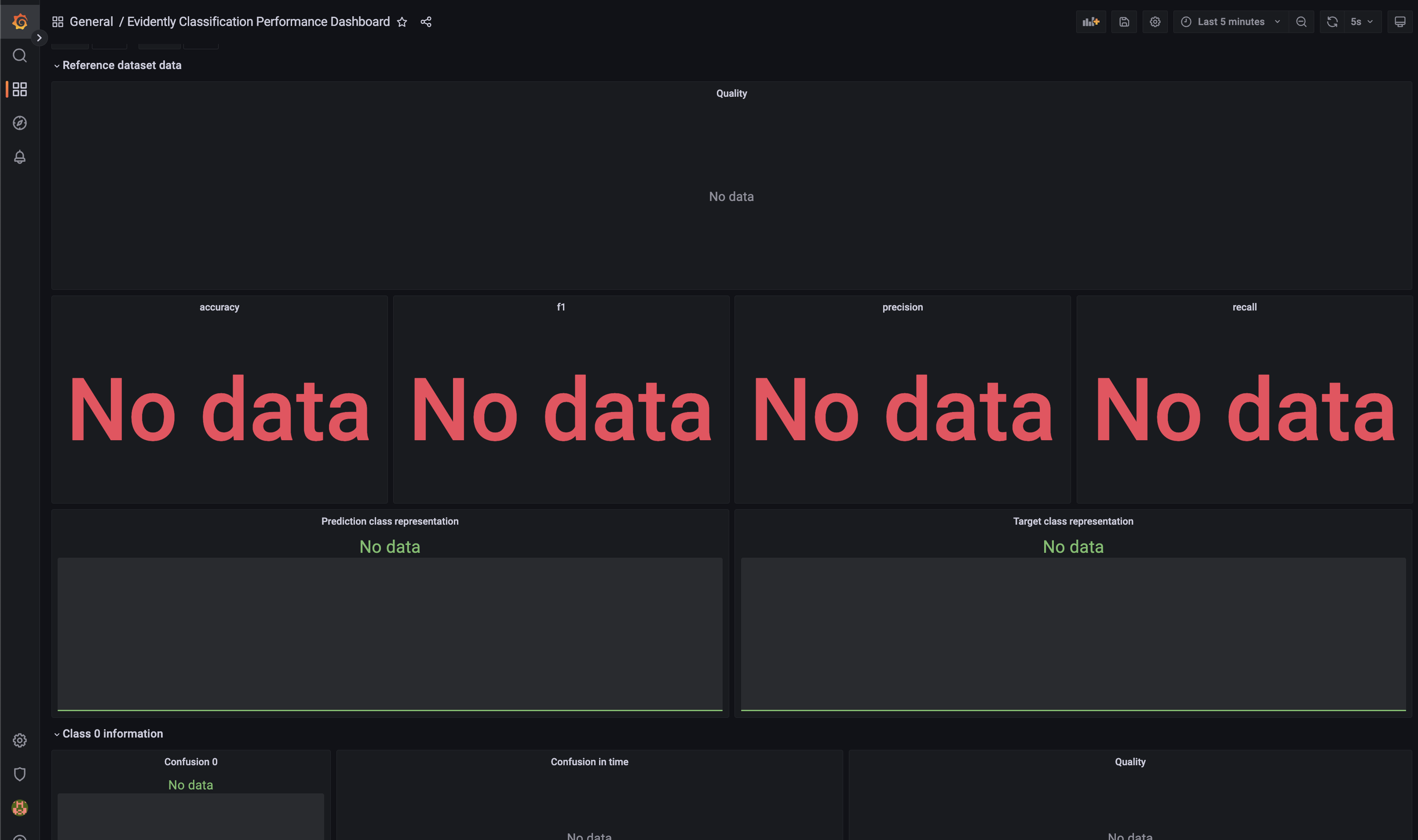
Dashboard này chứa các panels về model performance bao gồm:
-
Reference dataset dataQuality: Tổng hợp model performance metrics theo thời gianaccuracy,f1,precision,recall: Model performance metricsPrediction class representation: Số lượng các dự đoán theo classTarget class representation: Số lượng các label theo class
-
Class 0 information: Thông tin về class 0Confusion 0: Confusion matrix cho class 0Confusion in time: Giá trị của confusion matrix theo thời gianQuality: Tổng hợp model performance metrics cho class 0 theo thời gian
-
Class 1 information: Tương tự class 0
Alerts
Grafana Alerts cho phép kích hoạt cảnh báo khi một vấn đề về metrics xảy ra. Trong bài này, chúng ta sẽ tạo một cảnh báo đơn giản để cảnh báo khi dataset bị drift.
-
Ở sidebar bên phải của Grafana, click
Dashabords. Ở trang Dashboard, tạo Folder tên làAlerts. Folder này được dùng để lưu cảnh báo chúng ta sẽ tạo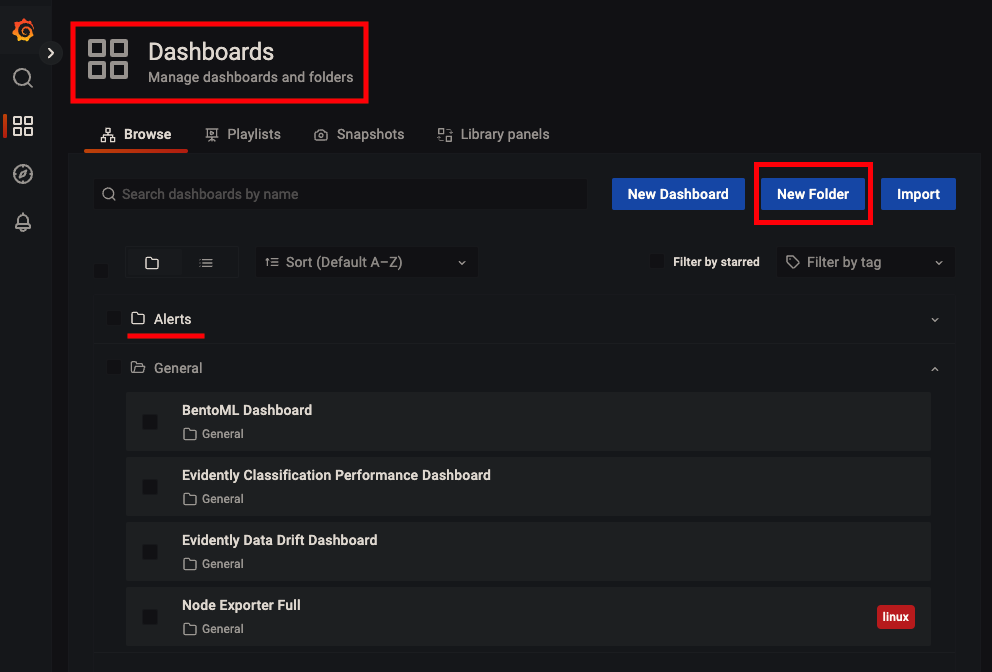
-
Ở sidebar bên phải của Grafana, bạn click vào
Alerting. Ở trangAlerting, tabAlert rules, click nútNew alert rule.
-
Trong trang tạo cảnh báo, tạo cảnh báo mới tên là
Data drift detection, điền các thông tin trong phần1. Set a query and alert conditionnhư ảnh dưới, với queryAlà: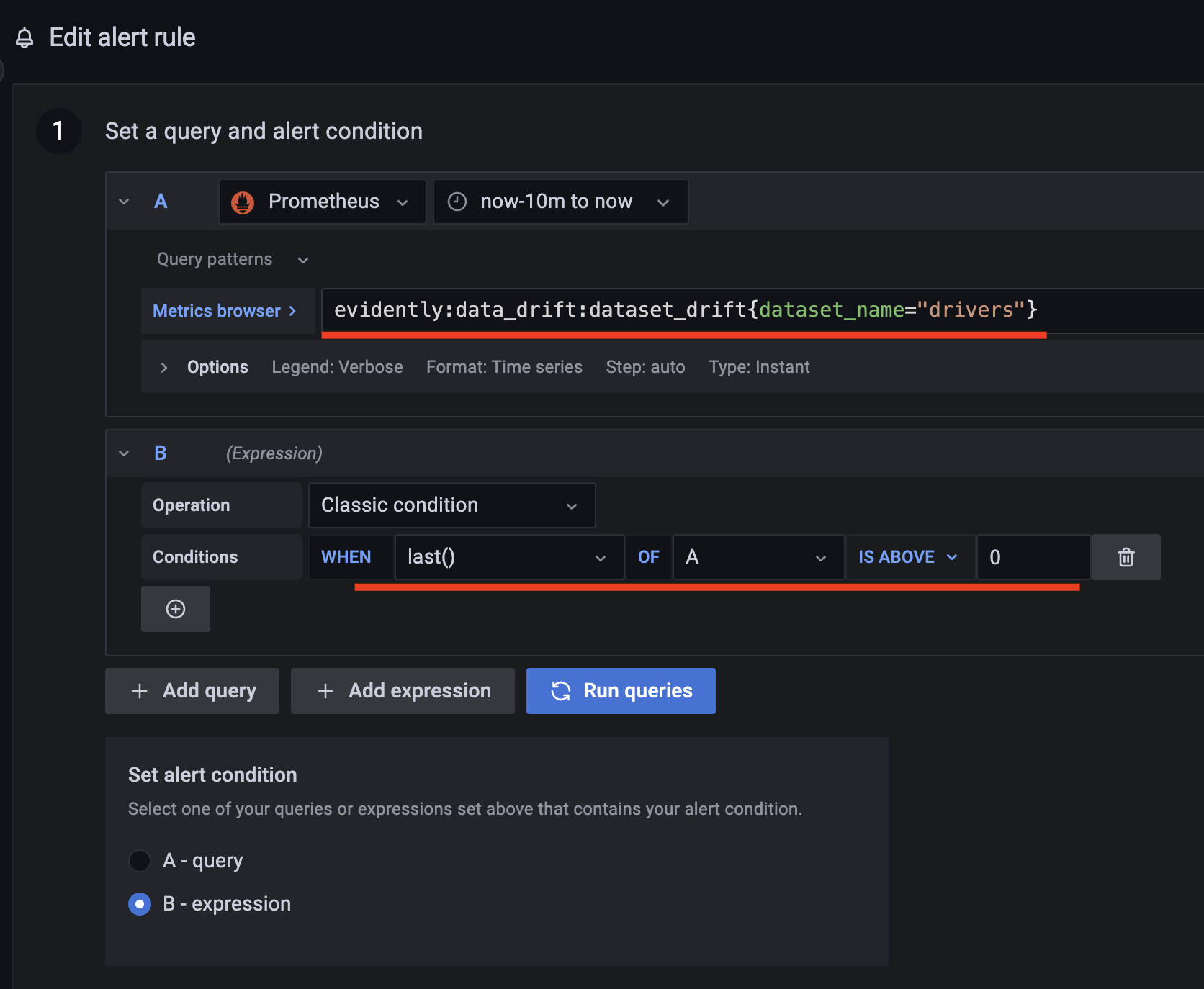
-
Phần
2. Alert evaluation behaviorvà3. Add details for your alert
-
Click
Save and exit
Info
Để cấu hình cách mà Alert được gửi đi, bạn vào tab Notification polices và thêm policy mới. Trong bài này, để đơn giản hơn chúng ta sẽ giữ nguyên policy mặc định của Grafana.
Thử nghiệm
Data bị drift
Sau khi thiết lập xong dashboards, chúng ta sẽ viết code để gửi request giả tới Online serving API. Code để gửi requests được đặt tại monitoring_service/src/mock_request.py.
- Hàm
construct_requesttạo payload dạng JSON để gửi tới Online serving API - Hàm
send_requestgửi payload trên tới Online serving API - Hàm
mainthực hiện quá trình gửi data - Đọc dataset chứa các features tuỳ thuộc vào loại data là
normal_datahaydrift_data - Đọc
request_data - Ghi đè dataset chứa các features vào file data source của Feast
- Xoá data ở cả Offline Feature Store và Online Feature Store
- Ghi data từ file data source của Feast vào Offline Feature Store
- Ghi data từ Offline Feature Store vào Online Feature Store
- Gửi lần lượt các request trong
request_datatới Online serving API
Để tiến hành thử nghiệm, bạn làm theo các bước sau.
-
Đảm bảo Online serving service đã chạy
-
Cập nhật Feature Store
- Triển khai code của Feature Store
-
Build docker image và chạy docker compose cho monitoring service
Tip
Định nghĩa về các env vars được dùng trong quá trình build image được lưu tại
monitoring_service/deployment/.env. Bạn có thể thay đổi nếu cần. -
Gửi 5 requests giả chứa
drift_data -
Đợi 30s, kiểm tra Evidently Data Drift Dashboard và Evidently Classification Performance Dashboard, kết quả sẽ giống như sau.
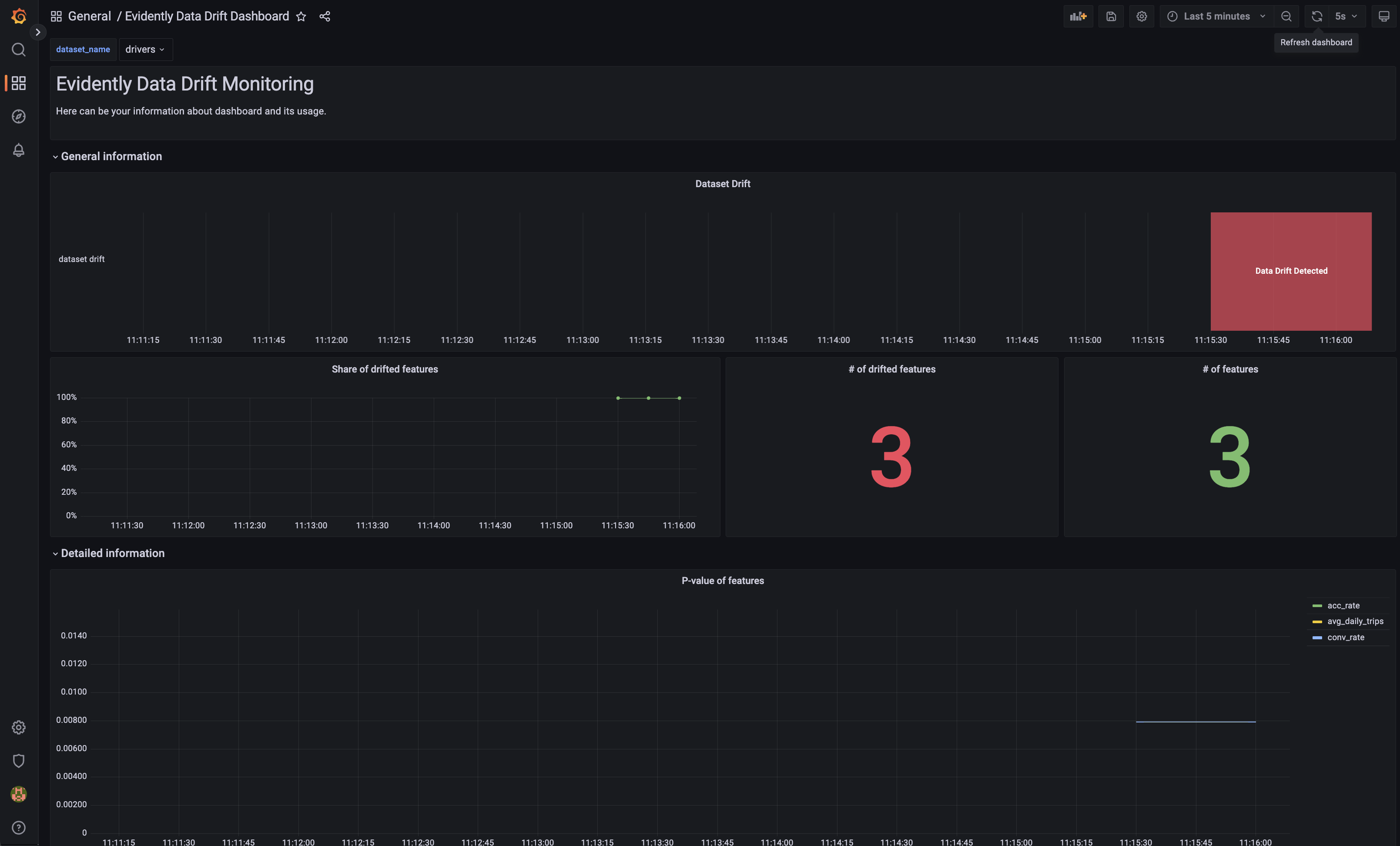
Evidently Data Drift Dashboard - Dataset drift 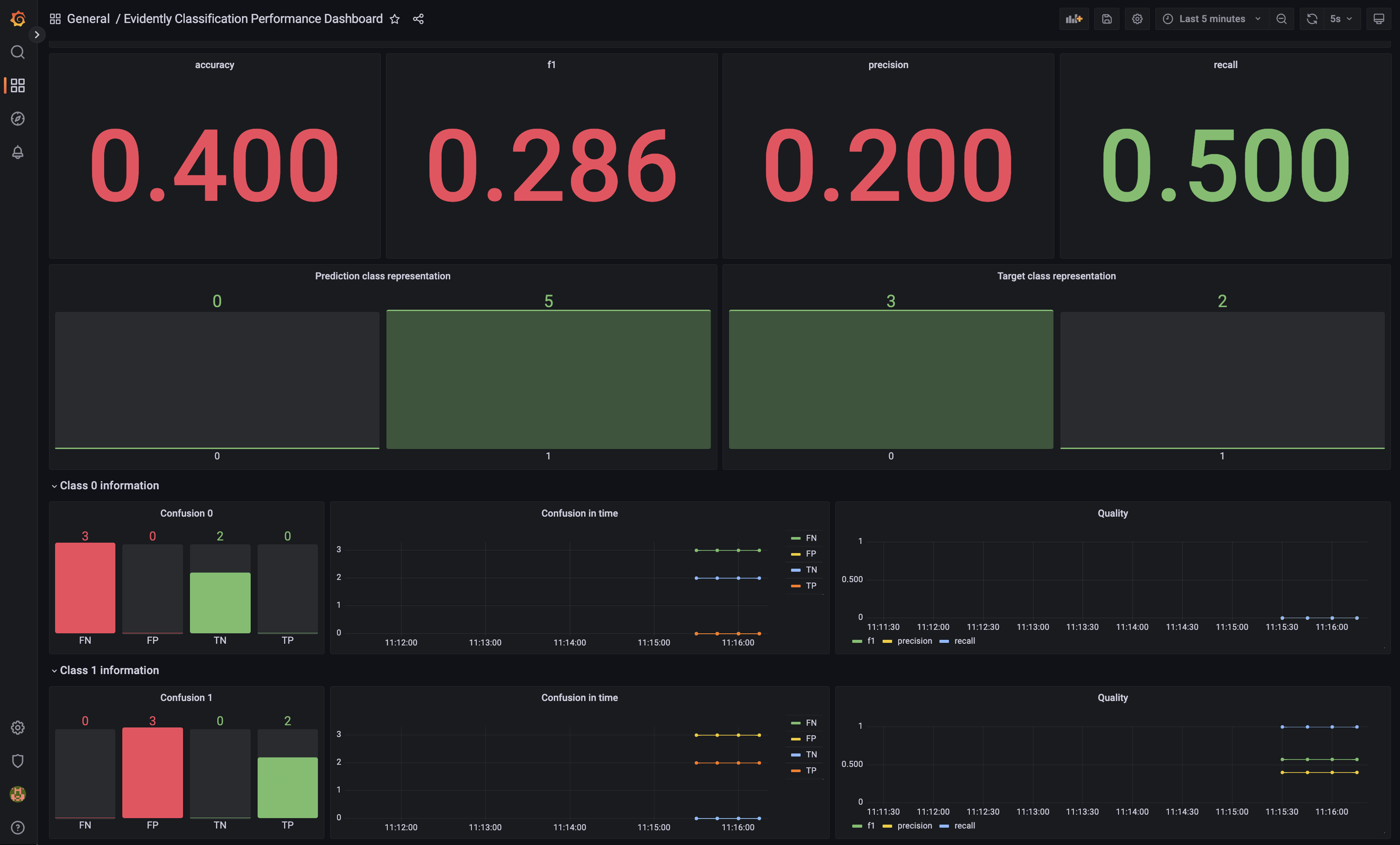
Evidently Classification Performance Dashboard -
Mở trang Grafana Alerting, bạn sẽ thấy cảnh báo
Data drift detectionđang ở trạng tháiFiring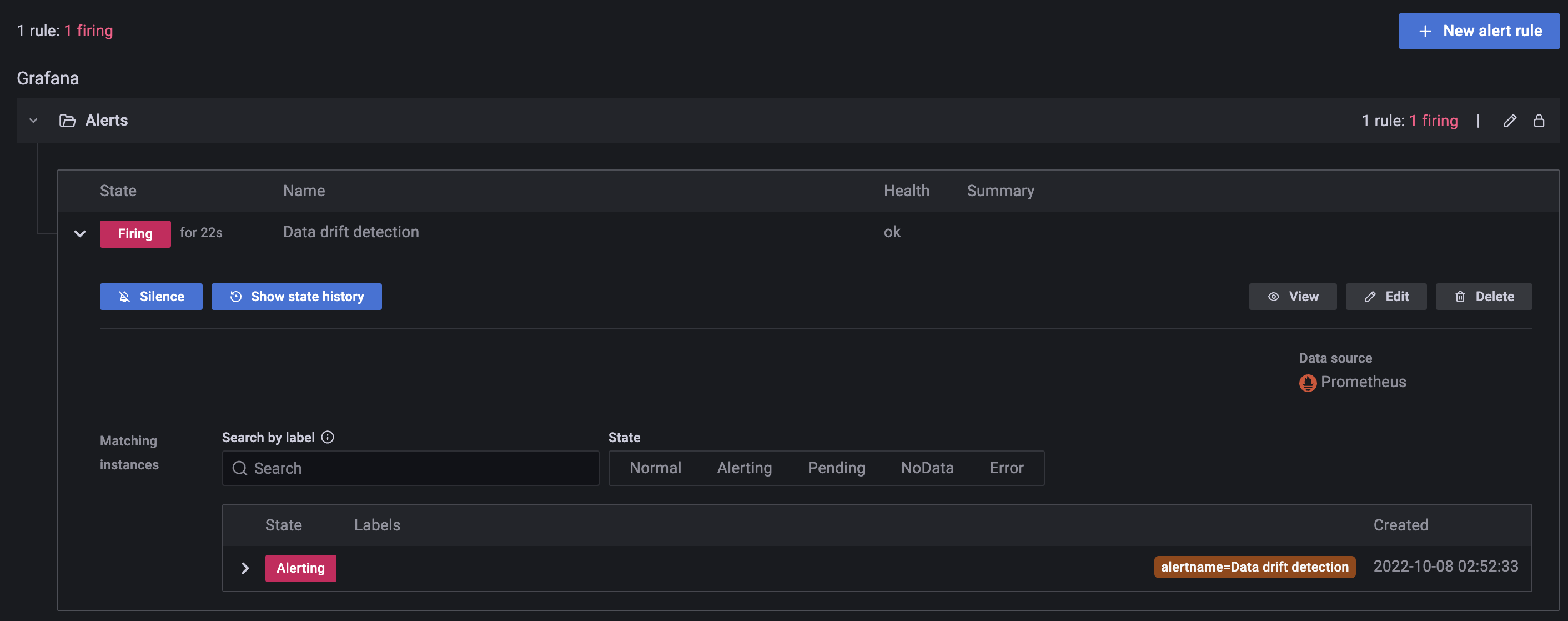
-
Click nút
Show state historyđể xem thời điểm của các trạng thái trong cảnh báo này.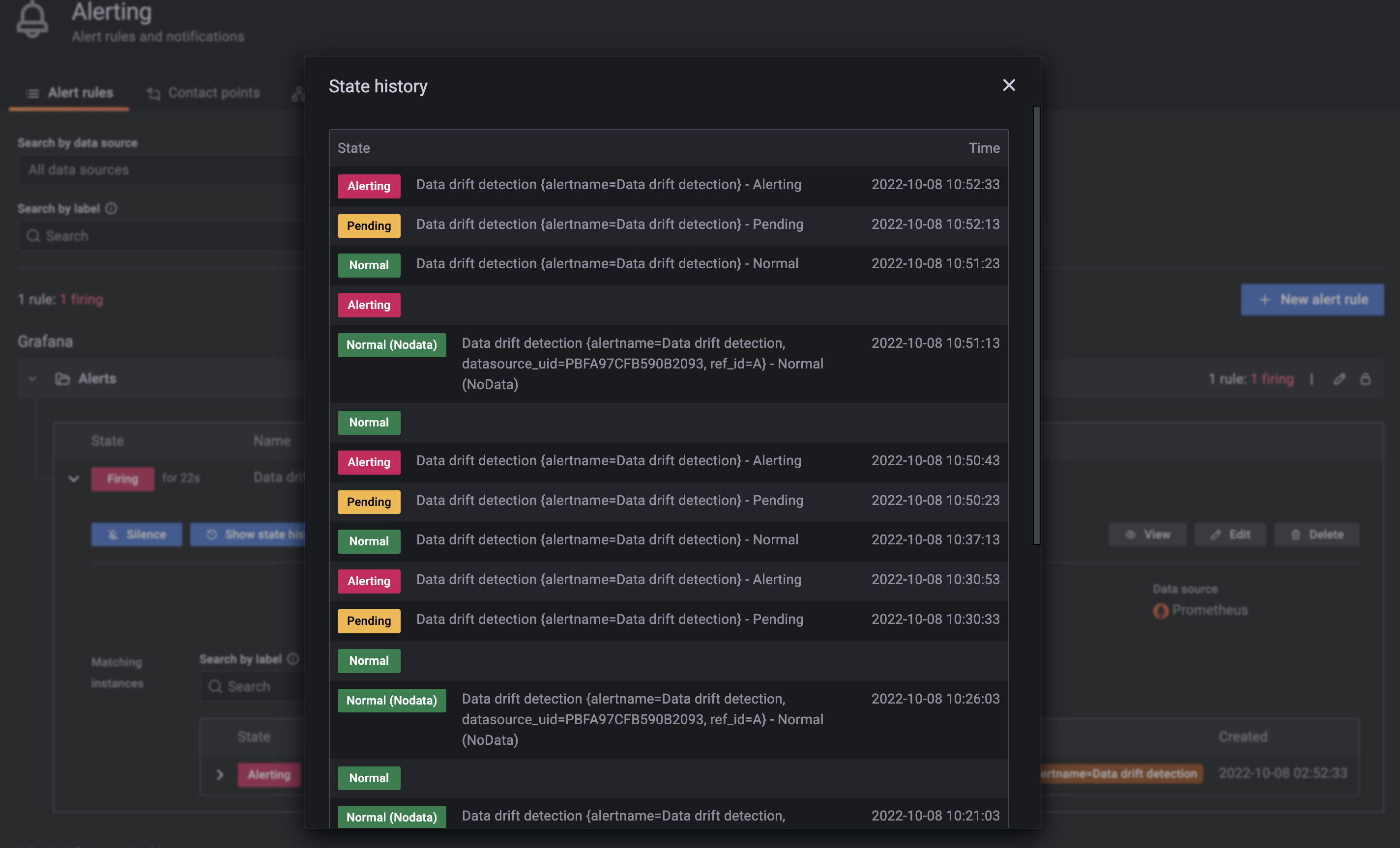
Data không bị drift
Tiếp theo, chúng ta sẽ test trường hợp data không bị drift. Bạn làm các bước sau.
-
Gửi 5 requests giả chứa
normal_datatới Online serving API -
Kiểm tra Evidently Data Drift Dashboard, bạn sẽ thấy thông tin Dataset không bị drift số features bị drift là 0. Ngoài ra, cảnh báo
Data drift detectioncũng đã ở trạng tháiNormal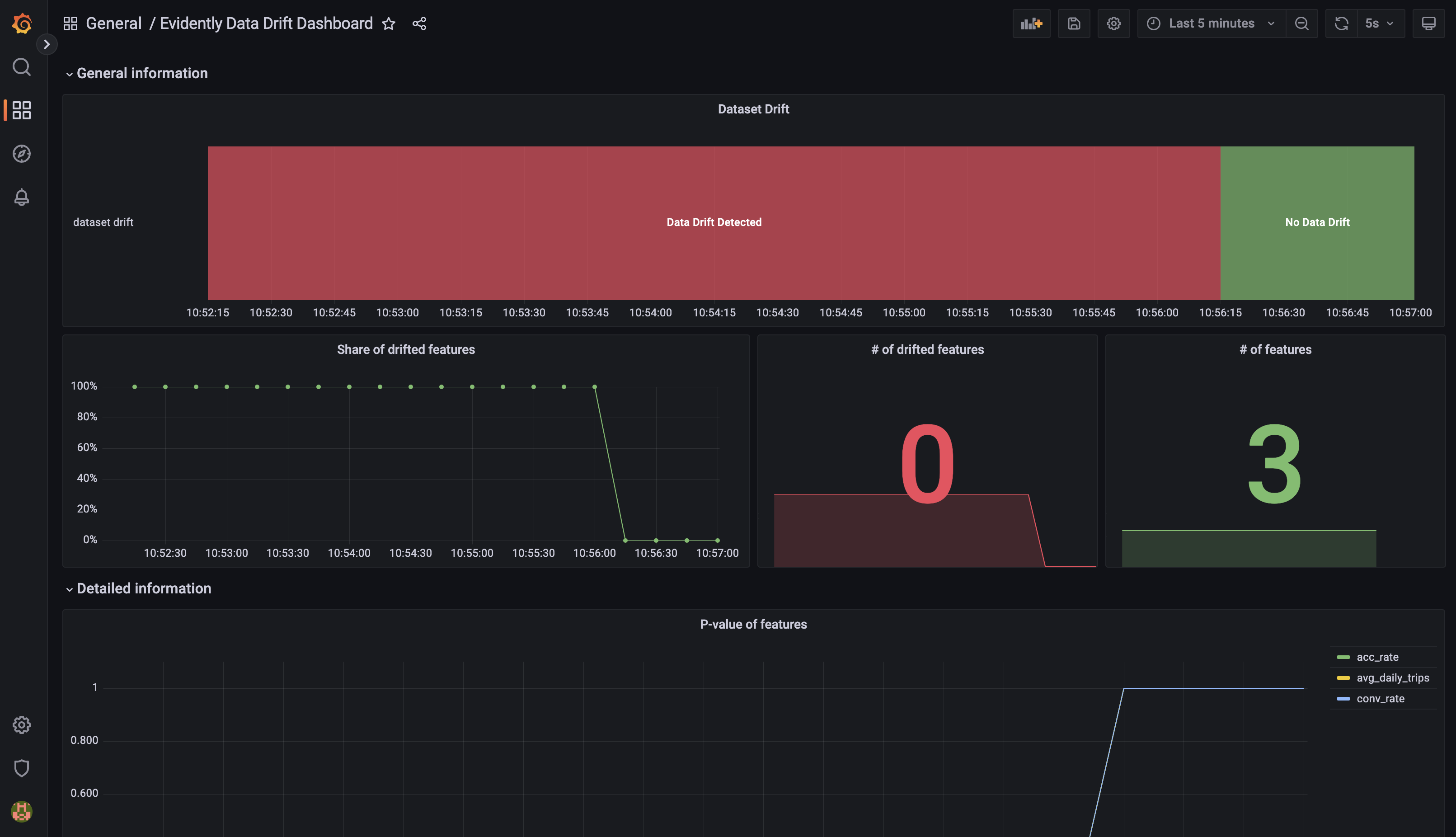
Evidently Data Drift Dashboard - Dataset không drift 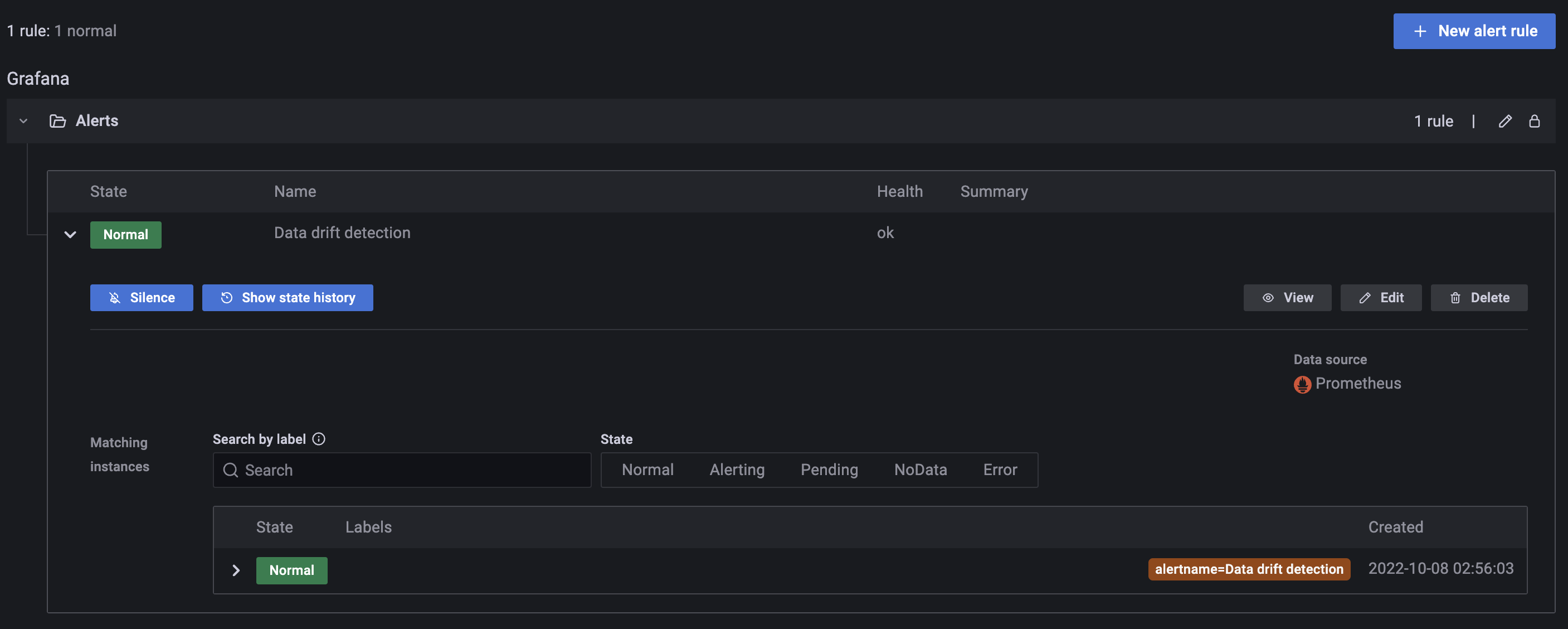
Alert Data drift detection ở trạng thái Normal
Tip
Nếu mở Kibana ra, bạn cũng sẽ thấy logs của Monitoring service được tự động thu thập nhờ chức năng tự động thu thập logs từ các containers của Filebeat
Tổng kết
Theo dõi và bảo trì luôn là một phần quan trọng trong quá trình phát triển một hệ thống phần mềm nói chung, đặc biệt là trong một hệ thống ML nói riêng. Trong bài Monitoring này, chúng ta đã biết về các metrics điển hình của hệ thống về data và về model mà một hệ thống ML thường theo dõi.
Chúng ta cũng đã phân tích và thiết kế một service khá phức tạp là Monitoring service. Bạn đã biết cách theo dõi các metrics của data, model như Phát hiện Data drift, Theo dõi model performance, triển khai và thiết lập cảnh báo trên Grafana. Trong thực tế, bạn có thể sẽ cần dùng Grafana alert để kích hoạt một tác vụ nào đó, ví dụ như kích hoạt training pipeline tự động khi phát hiện dataset bị drift hay đơn giản là gửi email thông báo về model performance tới Data Scientist, v.v.
Trong bài tiếp theo, chúng ta sẽ thiết lập và triển khai CI/CD cho các phần trong hệ thống ML. CI/CD giúp chúng ta tự động test và tự động triển khai các Airflow DAGs, cũng như là các services như Online serving service hay Monitoring service, thay vì gõ các lệnh thủ công trong terminal.