POC

Giới thiệu
Trong bài trước, chúng ta đã thực hiện bước đầu tiên của một dự án phần mềm, đó chính là thu thập các yêu cầu, phân tích vấn đề kinh doanh. Quá trình này giúp hiểu rõ và sâu hơn về vấn đề đang gặp phải, về những giải pháp tiềm năng, đồng thời lên kế hoạch để triển khai chúng.
Trong bài này, chúng ta bắt tay vào xây dựng một dự án POC. Dự án POC thử nghiệm các giải pháp nhanh chóng để chứng minh được tồn tại ít nhất một giải pháp giải quyết được vấn đề kinh doanh, trước khi bắt tay vào xây dựng các tính năng phức tạp khác. Vì ML được chọn làm giải pháp, nên việc cần làm đó là chứng minh rằng giải pháp ML là khả thi, bằng cách sử dụng MLOps platform đã được định nghĩa ở bài MLOps Platform.
Môi trường phát triển
Các thư viện bạn cần cài đặt cho môi trường phát triển được đặt tại training_pipeline/dev_requirements.txt. Bạn có thể dùng virtualenv, conda, hoặc bất kì công cụ nào để cài đặt. Phiên bản Python được sử dụng trong cả khoá học là 3.9.
Các MLOps tools được dùng trong bài này bao gồm:
- Jupyter notebook: thử nghiệm data, model
- MLflow: ML Metadata Store, Model Registry
Định nghĩa POC
Trong quá trình phân tích vấn đề kinh doanh, thông tin về data và quá trình xây dựng ML model đã được tổng hợp như sau.
| # | Câu hỏi | Trả lời |
|---|---|---|
| 1 | Data được lấy từ đâu? | Được tổng hợp bởi Data Engineer từ ứng dụng của công ty |
| 2 | Data sẽ được biến đổi và lưu trữ thế nào? | Được Data Engineer xử lý để thực hiện POC trước, format là parquet, tạm thời lưu ở Database nội bộ công ty |
| 3 | Feature tiềm năng? | conv_rate, acc_rate, avg_daily_trips |
| 4 | Model architecture tiềm năng? | Elastic Net |
| 5 | Dùng metrics nào để đánh giá model? | MSE, RMSE, R2 |
Khi định nghĩa dự án POC, chúng ta cần trả lời một câu hỏi quan trọng:
Thế nào là một dự án POC thành công?
Ở những dự án POC đầu tiên, ML model chưa được triển khai ra production mà chỉ được thử nghiệm offline. Do đó, chúng ta cần sử dụng các offline metrics để đánh giá. Cụ thể, cần đặt một threshold cho các metrics này. Ví dụ, sử dụng metric RMSE với một hạn mức (threshold) để định nghĩa dự án POC thành công là RMSE phải nhỏ hơn 0.5.
Ngoài RMSE cho bài toán logistic regression ra, một số metric khác cũng được sử dụng như:
- Sử dụng Accuracy, F1, AUC để đánh giá model performance cho bài toán classification
- Sử dụng thời gian training và inference của ML model để so sánh chi phí và lợi ích
- v.v.
Thu thập data
Ở dự án POC đầu tiên, do data pipeline chưa được hoàn thiện, nên data dùng để thử nghiệm được Data Engineer thu thập từ data sources, rồi chuyển giao data thô này cho Data Scientist (DS). DS sẽ thực hiện các công việc sau:
- Phân tích data để định nghĩa các cách biến đổi cho data. Các cách biến đổi này được dùng để xây dựng data pipeline
- Phân tích data, thử nghiệm và định nghĩa các cách biến đổi feature engineering cho data. Các cách biến đổi feature engineering này được dùng để xây dựng data pipeline
- Thử nghiệm các model architecture và hyperparameter. Cách train model được dùng để xây dựng training pipeline
Phân tích data
Trong phần này, Jupyter Notebook được dùng để viết code phân tích data và training code. Giả sử Data Engineering đã thu thập data từ data sources và chuyển giao cho chúng ta 2 file data:
training_pipeline/nbs/data/exp_driver_stats.parquet: chứa data của các tài xế, được ghi lại ở nhiều thời điểmtraining_pipeline/nbs/data/exp_driver_orders.csv: chứa thông tin về cuốc xe có hoàn thành hay không của các tài xế ở nhiều thời điểm
Hai file này chứa các cột chính với ý nghĩa tương ứng như sau:
| File | Cột | Ý nghĩa |
|---|---|---|
| exp_driver_stats.parquet | datetime | Thời gian record được ghi lại |
| driver_id | ID của tài xế | |
| conv_rate | Một thông số nào đó | |
| acc_rate | Một thông số nào đó | |
| avg_daily_trips | Một thông số nào đó | |
| exp_driver_orders.csv | event_timestamp | Thời gian record được ghi lại |
| driver_id | ID của tài xế | |
| trip_completed | Cuốc xe có hoàn thành không |
Source code được đặt tại training_pipeline/nbs/poc-training-code.ipynb.
- Đường dẫn tới data files
- Load data
- Định dạng lại cột
event_timestamp - Định nghĩa tên của cột chứa label
Tiếp theo, Data Scientist sẽ phân tích data để hiểu data. Quá trình này thường kiểm tra những thứ sau.
- Có feature nào chứa
nullkhông? Nên thaynullbằng giá trị nào? - Có feature nào có data không thống nhất không? Ví dụ: khác đơn vị (km/h, m/s), v.v
- Có feature hay label nào bị bias không? Nếu có thì do quá trình sampling hay do data quá cũ? Giải quyết thế nào?
- Các feature có tương quan không? Nếu có thì có cần loại bỏ feature nào không?
- Data có outlier nào không? Nếu có thì có nên xoá bỏ không?
- v.v
Mỗi một vấn đề về data trên sẽ có một hoặc nhiều cách giải quyết. Tuy nhiên, chúng ta sẽ không biết được ngay các cách giải quyết có hiệu quả hay không. Do vậy, quá trình kiểm tra và phân tích data này thường sẽ đi kèm với các thử nghiệm đánh giá model. Các metrics khi đánh giá model giúp đánh giá xem các giải pháp được thực hiện trên data có hiệu quả không. Vì tiến trình thường gặp của Machine Learning là thử nghiệm với data, model nên bước phân tích data này và bước training model như một vòng lặp được thực hiện lặp lại nhiều lần.
Vì các file data của chúng ta không có feature nào chứa null và để tập trung vào MLOps, chúng ta sẽ tối giản hoá bước phân tích data này và đi vào viết code train model.
Chuẩn bị data
Đầu tiên, features được tổng hợp từ DataFrame df_orig với labels từ DataFrame label_orig. Cụ thể, với mỗi record trong label_orig, chúng ta muốn lấy ra record mới nhất tương ứng trong df_orig với driver_id giống nhau. Record mới nhất tương ứng nghĩa là thời gian ở cột datetime trong df_orig sẽ xảy ra trước và gần nhất với thời gian ở cột event_timestamp trong label_orig. Ví dụ:
df_origchứa 2 records như sau
| index | datetime | driver_id | conv_rate | acc_rate | avg_daily_trips |
|---|---|---|---|---|---|
| 1 | 2022-12-01 | 1001 | 0.1 | 0.1 | 100 |
| 2 | 2022-11-01 | 1001 | 0.2 | 0.2 | 200 |
| 3 | 2022-10-01 | 1001 | 0.3 | 0.3 | 300 |
| 4 | 2022-09-01 | 1001 | 0.4 | 0.4 | 400 |
label_origchứa 2 records như sau
| index | event_timestamp | driver_id | trip_completed |
|---|---|---|---|
| 1 | 2022-12-15 | 1001 | 1 |
| 2 | 2022-09-15 | 1001 | 0 |
- Data mà chúng ta muốn tổng hợp gồm 2 records như sau
| index | event_timestamp | driver_id | trip_completed | conv_rate | acc_rate | avg_daily_trips |
|---|---|---|---|---|---|---|
| 1 | 2022-12-15 | 1001 | 1 | 0.1 | 0.1 | 100 |
| 2 | 2022-09-15 | 1001 | 0 | 0.4 | 0.4 | 400 |
-
Giải thích
- Features từ
index 1ởdf_origđược lấy ra cho recordindex 1ởlabel_orig, vì feature đó là mới nhất (2022-12-01) so vớievent_timestampcủa record ởindex 1(2022-12-15) tronglabel_orig - Tương tự, features từ
index 4ởdf_origđược lấy ra cho recordindex 2ởlabel_orig, vì feature đó là mới nhất và xảy ra trước (2022-09-01) so vớievent_timestampcủa record ởindex 2(2022-09-15) tronglabel_orig
- Features từ
Code để tổng hợp features và labels như dưới đây.
- Nhóm features vào các nhóm theo
driver_id - Hàm xử lý mỗi hàng trong
label_orig - Lấy ra các hàng trong
df_origcủa một tài xế - Lấy ra các hàng trong
df_origcódatetime<=event_timestampcủa hàng hiện tại tronglabel_orig - Sắp xếp các hàng theo cột
datetime - Lấy ra hàng ở thời gian mới nhất
- Thêm các cột cần thiết vào
- Biến thành
Series(một hàng) và return - Loại bỏ các cột không cần thiết
Training code
Sau khi tổng hợp features và labels vào data_df, DataFrame này được chia thành training set và test set. Các bước train model và đánh giá model được thực hiện như dưới đây.
- Chọn các features để train
- Tạo training set và test set
- Train model
- Đánh giá model
Chúng ta cần thử nghiệm rất nhiều bộ feature, nhiều model architecture với các bộ hyperparameter khác nhau. Để có thể tái lập kết quả training, cần phải biết được thử nghiệm nào dùng bộ feature nào, model architecture, với các hyperparameter nào. Trong khoá học này, chúng ta sẽ sử dụng MLOps Platform đã được giới thiệu trong bài MLOps Platform và cụ thể là MLflow sẽ đóng vai trò chính giúp chúng ta theo dõi các thông tin trên hay ML metadata của các lần thử nghiệm.
Theo dõi thử nghiệm
MLflow là một open-source platform để quản lý vòng đời và các quy trình trong một hệ thống ML. Một trong những chức năng của MLflow mà chúng ta sử dụng đó là chức năng theo dõi ML metadata. Code của phần này được đặt tại notebook training_pipeline/nbs/poc-integrate-mlflow.ipynb. Logic của code giống như notebook training_pipeline/nbs/poc-training-code.ipynb, chỉ có thêm đoạn code để tích hợp MLflow vào. Bạn hãy làm theo các bước sau để tích hợp MLflow.
-
Clone github repo mlops-crash-course-platform, chạy MLflow server trên môi trường local
-
Đi tới URL http://localhost:5000 để kiểm tra xem MLflow server đã được khởi tạo thành công chưa
-
Trong notebook
training_pipeline/nbs/poc-integrate-mlflow.ipynb, các bạn để ý đoạn code sau được thêm vào ở đoạn code training để tích hợp MLflow vào đoạn code trainingtraining_pipeline/nbs/poc-integrate-mlflow.ipynb - Vì
sklearnđược dùng để train model, dòng này tự động quá trình log lại các hyperparameter và các metrics trong quá trình training. Xem thêm ở đây để biết thêm thông tin về các training framework được MLflow hỗ trợ tự động log ML metadata.
- Vì
-
Đoạn code sau để log lại các hyperparameter và metric
- Đặt tên cho lần chạy
- Log lại feature được dùng
- Log lại hyperparameter
- Log lại metric sau khi test trên test set
- Log lại model
-
Mở MLflow trên browser, bạn sẽ thấy giao diện như sau.
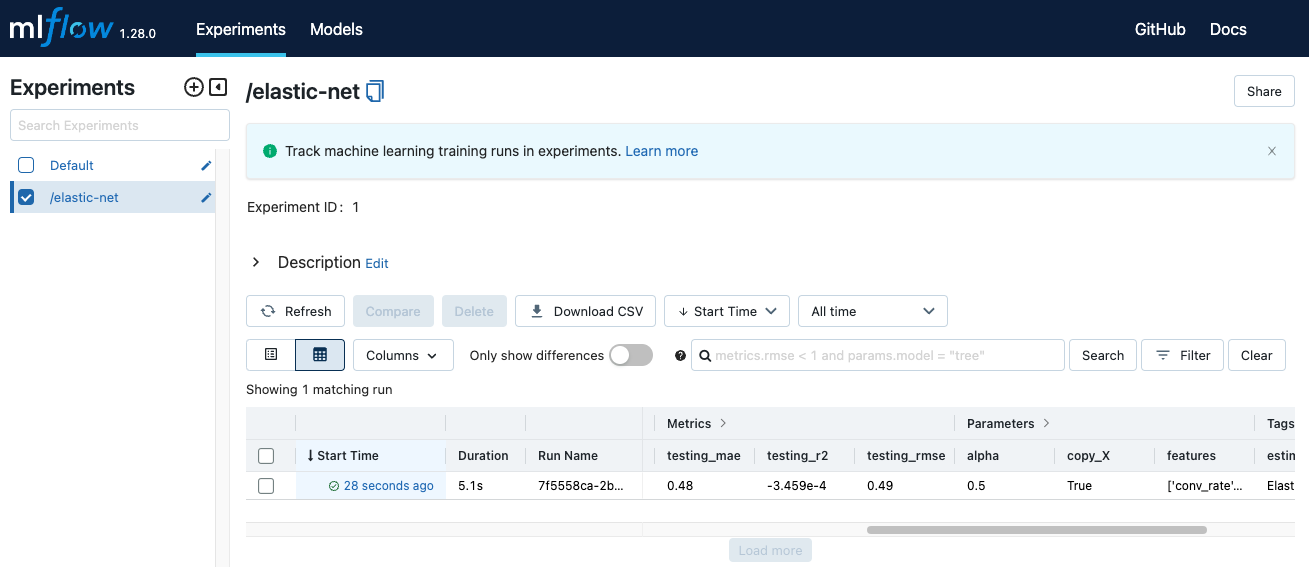
Mọi thông tin chúng ta log lại mỗi lần thử nghiệm đã được lưu lại. Bạn có thể xem thêm thông tin chi tiết về một lần chạy bằng cách ấn vào cột
Start timecủa lần chạy đó.
Theo dõi features
Trong phần trước, chúng ta đã coi bộ feature mà chúng ta sử dụng trong quá trình training như một hyperparameter và dùng MLflow để log lại. Tuy nhiên, đây chưa phải giải pháp tối ưu để theo dõi các feature trong quá trình thử nghiệm.
Mục đích của việc theo dõi các feature là để có thể tái lập kết quả của một thử nghiệm. Chỉ bằng việc lưu lại tên các feature được dùng thì không đảm bảo được sẽ tạo lại được kết quả, vì có thể feature bị đổi tên hoặc tên vẫn giữ nguyên nhưng cách biến đổi để sinh ra feature đó bị thay đổi. Do đó, việc theo dõi các feature này không chỉ là theo dõi tên của các feature, mà cả quy trình sinh ra các feature đó.
Ở giai đoạn POC, vì chưa có đủ nguồn lực để xây dựng cơ sở hạ tầng đủ mạnh để hỗ trợ việc theo dõi quy trình tạo ra feature, nên chúng ta chỉ kì vọng sẽ theo dõi được tên các feature là đủ. Trong các bài tiếp theo, chúng ta sẽ học cách theo dõi version của quy trình biến đổi feature và tích hợp version đó vào quá trình training.
Tổng kết
Qua nhiều lần thử nghiệm data và model, ngoài việc chứng minh giải pháp ML là khả thi, chúng ta sẽ hiểu rõ hơn về vấn đề kinh doanh, giải pháp tiềm năng, cách đánh giá các giải pháp đó một cách hiệu quả. Các đầu ra này sẽ được dùng để cập nhật lại các định nghĩa của vấn đề kinh doanh, các cách biến đổi data để xây dựng data pipeline, training code để xây dựng training pipeline và serving code để xây dựng model serving component.
Trong bài tiếp theo, chúng ta sẽ xây dựng data pipeline, một trong những pipeline phức tạp nhất của hệ thống.